 RARE Technologies
RARE Technologies10th August : PyCon Delhi
Planning to give some open space and lightening talks on gensim at pycon India in September. Hopefully we’ll also be able to organize a sprint there.
1st August : Plugging in your own model
You can use the topic coherence pipeline to plug in your own topic model too. If you can extract the topics keywords from your model, you can plug it into the coherence pipeline using the “topics” parameter. I have also submit a PR on this recently here
22nd July : Pro-Tip
To make LDA behave like LSA, you can rank the individual topics coming out of LDA based on their coherence score by passing the individual topics through some coherence measure and only showing say the top 5 topics. Great use-case for the topic coherence pipeline!
21st July : c_uci and c_npmi
Added c_uci and c_npmi coherence measures to gensim. They take much lesser time than c_v but are much more accurate than u_mass however less accurate than c_v. These can thus act as good middle-out algorithms per-say. You can find the PR here. Added them to the benchmark testing too and they gave decent results.
15th July : Sliding windows
I reverted the sliding window algorithm back to the old one since that is the one used in the paper. I gave a correlation value of 0.61 on 20NG and is still running on movies (will take about 20 hrs to run. 2 more hours to go as of now.) The new sliding window was much faster (run on movies in 26 minutes) and gave a correlation of 0.61 too. I guess this is something I can study further.
14th July : 20NG and movies
Sorry for not updating here since the last few days. Here’s what happened over the last few days. I fixed the c_v backtracking problem (will post a pr soon) and the sliding window problem (it wasn’t really a problem actually. It worked fine.). I ran c_v on 20NG but got a correlation value of 0.45. The paper states a correlation value of 0.65. This was a bit disappointing but can’t really blame the algorithm. The number of documents and vocabulary size is not the same as in the paper. Here are the numbers I should be getting to reproduce the values from the paper:
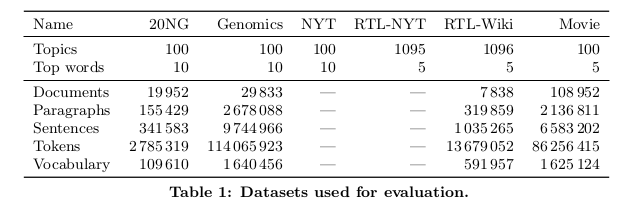
Here are the values from the paper:
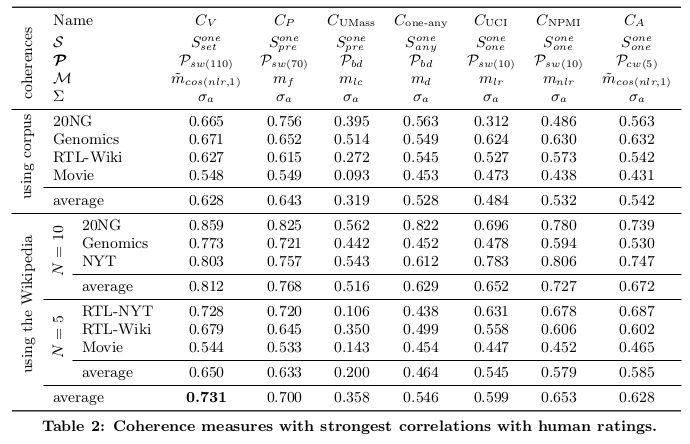
I’ve uploaded the notebook for the benchmark testing outputs of c_v and u_mass here. The values are quite different. I’ve also email Mr. Roeder to ask about the preprocessing that had been done for preparing the datasets.
I also did the benchmark testing on the movies dataset wherein, again, I got values different from that in the paper. Here’s the output:
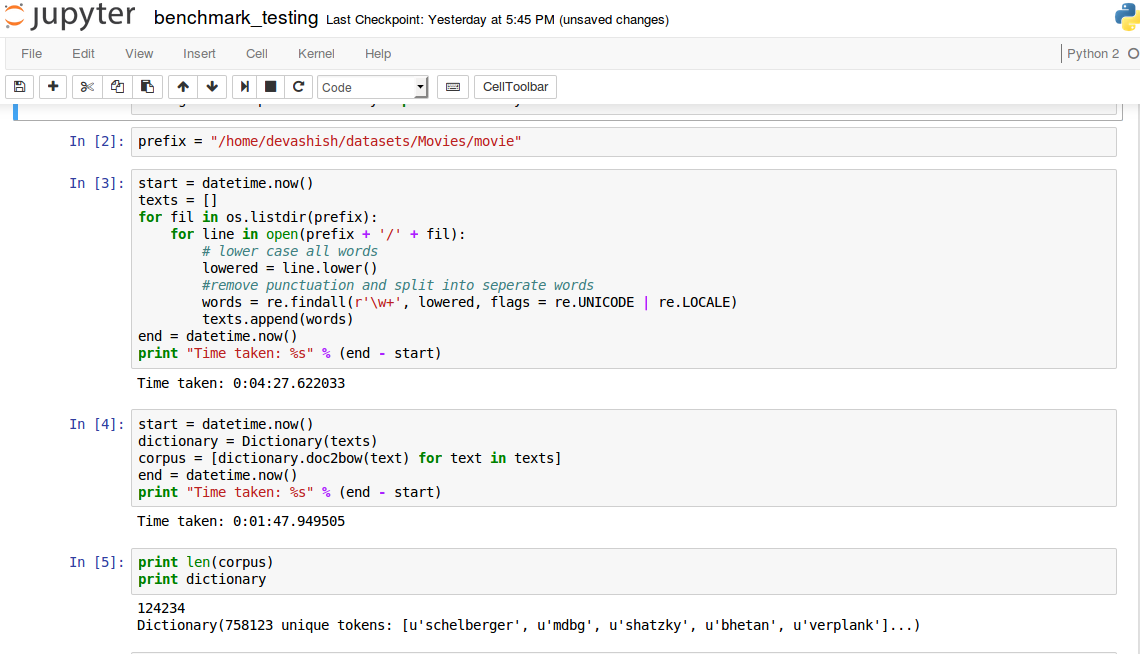
The u_mass correlation is 0.135 which is close to the value in the paper. I haven’t completed c_v correlation yet. However the time it is taking to run on just one topic is about 12 minutes. I then rewrote the backtracking algorithm and shaved off a minute but still it’s too much. The time profiling output says that the sliding window is taking 99.9% of the time. I think my logic for the sliding window might be wrong.
——————————BREAKING NEWS—————————-
C_V SLIDING WINDOW REWRITTEN.
NOW RUNS ON FULL MOVIES DATASET IN 26 MINUTES.
GIVING CORRELATION OF 0.51. 0.54 EXPECTED.
FIND THE GIST HERE: https://gist.github.com/dsquareindia/22c77be7ee5b10c54d53560951e33fbe
8th July : Benchmark testing pivot
I decided yesterday to instead do benchmark testing against Palmetto using the 20NG dataset. It is much easily preprocessed since it can be accessed via the scikit-learn API. I am using the topics from topics20NG.txt and the human ratings from gold20NG.txt from here. The correlation is calculated using pearson’s r as suggested in the paper. The r value for u_mass coherence is coming out to be 0.46 on 99 topics out of 100. I’m getting a KeyError on 1 topic since for some reason it’s not there in the dictionary. For calculating correlation for c_v I need to fix a small bug in the backtracking dictionary as I mentioned above and also need to change the window size to 110. You can find the intermediate gist here.
7th July : Starting to work with pyLucene
To perform the final benchmark testing using RTL-Wiki, I asked Mr Roeder from aksw if he had any script to parse through the .html dump. He didn’t have a script but had the preprocessed corpus as a java lucene corpus. There exists a python lucene extension to work with the java lucene which I am setting up now. You can find it here. A huge shout out to Mr Roeder for all the help!
4th July : Testing correctness of c_v on toy example
Here’s the test script I’ve written:
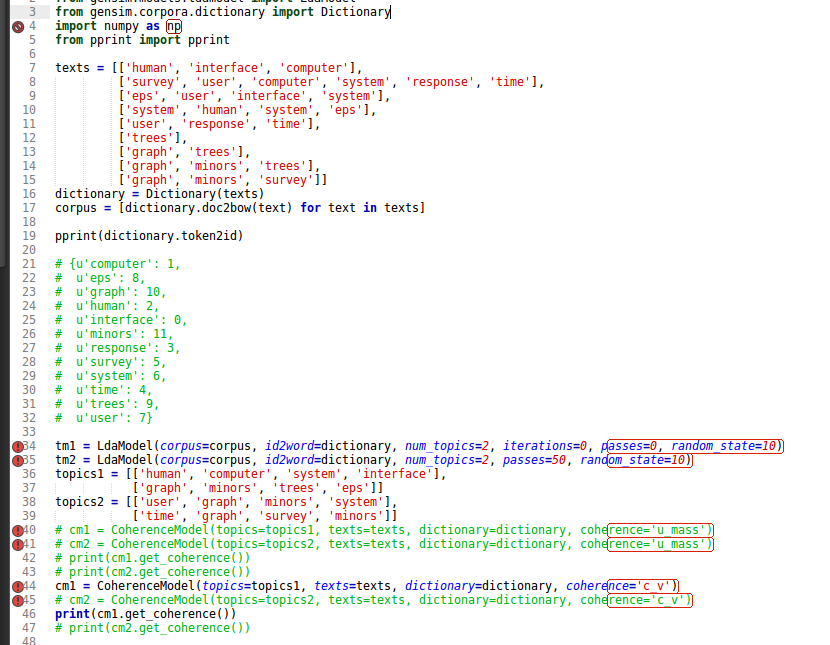
- Mapping of topic to id is working fine
- Segmentation of topics is alright
- per_topic_posting with sliding window is working fine
- We’ll do confirmation measure in different parts
- Can optimise backtracking. Cosine similarity between (a, b) and (b, a) is always equal. Not accounted currently.
- Still working.
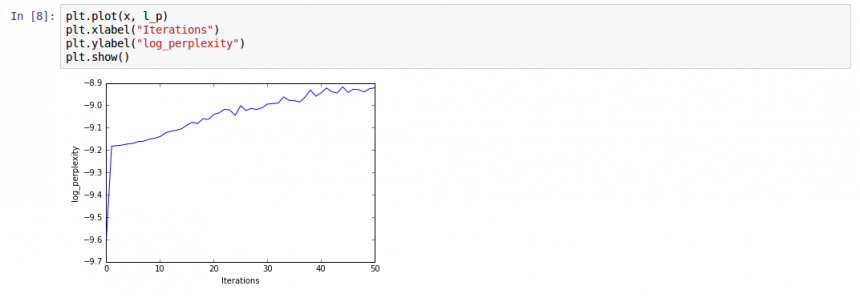
30th June : Testing with log_perplexity
Just as another small check, we decided to check the behavior of log_perplexity too of the LdaModel. Here’s the snippet and the graph obtained:
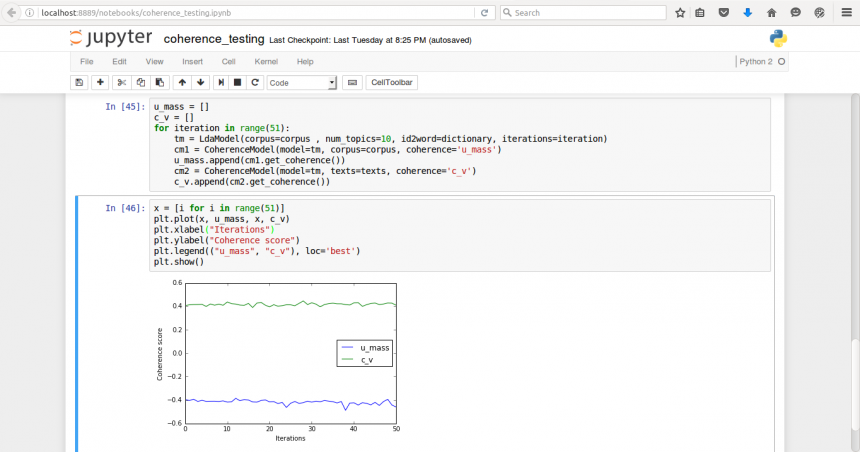
29th June : Testing coherence on Lee corpus
After consistently seeing some failing test in my latest pr I decided to do a small quantitative analysis of iterations vs coherence value. Intuitively, LdaModel should be coming up with better or more human interpretable topics as the number of iterations increases and hence the coherence value should keep increasing. The graph however shows otherwise. Will have to dig deeper into this.
28th June : Getting involved in the mailing list
I tried to answer a question concerning transforming an LdaMallet model to an LdaModel in gensim here. I also added a changelog to my PR so it’s complete now. I am also thinking of adding a normalization model tutorial notebook so as make users more comfortable with the change which got merged a while a ago. Parsing the RTL wiki and making the pipeline run a big dataset like 20NG is the next task at hand.
27th June : Travel days
I will be traveling today from New York to New Delhi so unfortunately I won’t be able to work too much today. Will be reaching Delhi by around 3pm IST tomorrow.
26th June : Copa America Final!
Went to watch the copa america final for the weekend at MetLife stadium(I’m a huge football fan btw)!
24th June : Self review and cleaning up my PR
Today I did a self-review and then a clean up of my PR, i.e. added some documentation, added a test suite for CoherenceModel and aggregation module and removed redundant code. The beta version of topic coherence has been released. Can’t wait for user feedback now! The official review process should start now. Next week I will be working on performing benchmark testing against Palmetto using the RTL-Wiki corpus.
23rd June : Integrating gensim wrappers
I have added support for accepting LdaVowpalWabbit and the LdaMallet wrapper. Had to use the function _get_topics() for getting the topics out of the former and the wordtopics member variable for the latter. So now almost all LDA models offered by gensim are now supported by this API.
21st, 22nd June : Understanding gensim dictionaries and HashDictionaries
Was having some problems with the test failing in the topic coherence pr. Just learnt how the random seeding in the hashing function is different in python2 and python3. Have a look at the stackoverflow issue. Tests pass now after using HashDictionary instead of dictionary.
20th June : To yield or not to yield
Still haven’t been able to connect to the RaRe servers. In the meantime I decided to do away with the idea of making the functions in the segmentation module generators since the output will just be around 3*100 segmentations most of the time which is not that memory intensive.
16th, 17th June : Data science meetup and connecting to the RaRe servers
I went for a python data science meetup yesterday, the topic of which was “Mapping the World of Music into Vector Spaces”. I even met Lev and Daniel (@droudy) there! You can check out the slides for that presentation here.

Daniel, Lev and I having Borscht and Kvass

Comments 1
Well. i don’t know if i can be in such student incubator. Isn’t it difficult? But on the other hand you help each other, i think there you all have found the “second” family)) If i were with you i won’t help you a kot. lol))