Tutorial: automatic summarization using Gensim
This module automatically summarizes the given text, by extracting one or more important sentences from the text. In a similar way, it can also extract keywords. This tutorial will teach you to use this summarization module via some examples. First, we will try a small example, then we will try two larger ones, and then we will review the performance of the summarizer in terms of speed.
This summarizer is based on the "TextRank" algorithm, from an article by Mihalcea et al. This algorithm was later improved upon by Barrios et al. in another article, by introducing something called a "BM25 ranking function".
This tutorial assumes that you are familiar with Python and have installed Gensim.
Note: Gensim's summarization only works for English for now, because the text is pre-processed so that stopwords are removed and the words are stemmed, and these processes are language-dependent.
Small example
First of all, we import the function "summarize".
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
from gensim.summarization import summarize
We will try summarizing a small toy example; later we will use a larger piece of text. In reality, the text is too small, but it suffices as an illustrative example.
text = "Thomas A. Anderson is a man living two lives. By day he is an " + \
"average computer programmer and by night a hacker known as " + \
"Neo. Neo has always questioned his reality, but the truth is " + \
"far beyond his imagination. Neo finds himself targeted by the " + \
"police when he is contacted by Morpheus, a legendary computer " + \
"hacker branded a terrorist by the government. Morpheus awakens " + \
"Neo to the real world, a ravaged wasteland where most of " + \
"humanity have been captured by a race of machines that live " + \
"off of the humans' body heat and electrochemical energy and " + \
"who imprison their minds within an artificial reality known as " + \
"the Matrix. As a rebel against the machines, Neo must return to " + \
"the Matrix and confront the agents: super-powerful computer " + \
"programs devoted to snuffing out Neo and the entire human " + \
"rebellion. "
print 'Input text:'
print text
To summarize this text, we pass the raw string data as input to the function "summarize", and it will return a summary.
Note: make sure that the string does not contain any newlines where the line breaks in a sentence. A sentence with a newline in it (i.e. a carriage return, "\n") will be treated as two sentences.
print 'Summary:'
print summarize(text)
Use the "split" option if you want a list of strings instead of a single string.
print summarize(text, split=True)
You can adjust how much text the summarizer outputs via the "ratio" parameter or the "word_count" parameter. Using the "ratio" parameter, you specify what fraction of sentences in the original text should be returned as output. Below we specify that we want 50% of the original text (the default is 20%).
print 'Summary:'
print summarize(text, ratio=0.5)
Using the "word_count" parameter, we specify the maximum amount of words we want in the summary. Below we have specified that we want no more than 50 words.
print 'Summary:'
print summarize(text, word_count=50)
As mentioned earlier, this module also supports keyword extraction. Keyword extraction works in the same way as summary generation (i.e. sentence extraction), in that the algorithm tries to find words that are important or seem representative of the entire text. They keywords are not always single words; in the case of multi-word keywords, they are typically all nouns.
from gensim.summarization import keywords
print 'Keywords:'
print keywords(text)
Larger example
Let us try an example with a larger piece of text. We will be using a synopsis of the movie "The Matrix", which we have taken from this IMDb page.
In the code below, we read the text file directly from a web-page using "requests". Then we produce a summary and some keywords.
import requests
text = requests.get('http://rare-technologies.com/the_matrix_synopsis.txt').text
print 'Summary:'
print summarize(text, ratio=0.01)
print '\nKeywords:'
print keywords(text, ratio=0.01)
If you know this movie, you see that this summary is actually quite good. We also see that some of the most important characters (Neo, Morpheus, Trinity) were extracted as keywords.
Another example
Let's try an example similar to the one above. This time, we will use the IMDb synopsis of "The Big Lebowski".
Again, we download the text and produce a summary and some keywords.
import requests
text = requests.get('http://rare-technologies.com/the_big_lebowski_synopsis.txt').text
print 'Summary:'
print summarize(text, ratio=0.01)
print '\nKeywords:'
print keywords(text, ratio=0.01)
This time around, the summary is not of high quality, as it does not tell us much about the movie. In a way, this might not be the algorithms fault, rather this text simply doesn't contain one or two sentences that capture the essence of the text as in "The Matrix" synopsis.
The keywords, however, managed to find some of the main characters.
Performance
We will test how the speed of the summarizer scales with the size of the dataset. These tests were run on an Intel Core i5 4210U CPU @ 1.70 GHz x 4 processor. Note that the summarizer does not support multithreading (parallel processing).
The tests were run on the book "Honest Abe" by Alonzo Rothschild. Download the book in plain-text here.
In the plot below, we see the running times together with the sizes of the datasets. To create datasets of different sizes, we have simply taken prefixes of text; in other words we take the first n characters of the book. The algorithm seems to be polynomial in time, so one needs to be careful before plugging a large dataset into the summarizer.
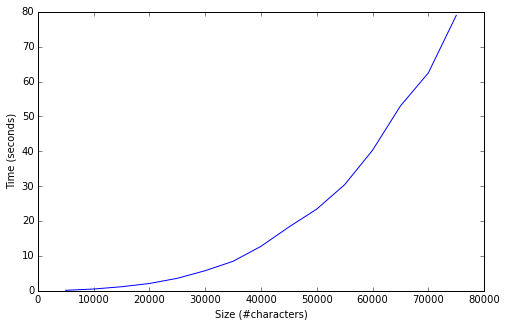
Text-content dependent running times
The running time is not only dependent on the size of the dataset. For example, summarizing "The Matrix" synopsis (about 36 000 characters) takes about 3.1 seconds, while summarizing 35 000 characters of this book takes about 8.5 seconds. So the former is more than twice as fast.
One reason for this difference in running times is the data structure that is used. The algorithm represents the data using a graph, where vertices (nodes) are sentences, and then constructs weighted edges between the vertices that represent how the sentences relate to each other. This means that every piece of text will have a different graph, thus making the running times different. The size of this data structure is quadratic in the worst case (the worst case is when each vertex has an edge to every other vertex).
Another possible reason for the difference in running times is that the problems converge at different rates, meaning that the error drops slower for some datasets than for others.