 RARE Technologies
RARE Technologies
Extraction of hand-written data from scanned insurance forms
Case study: AXA
THE BUSINESS CHALLENGE
AXA is one of the world leaders in finance, offering complex services in health and property insurance, pension savings and investments to more than 102 million clients worldwide.
As part of optimizing its services, AXA CZ/SK wished to increase the efficiency and reduce cost of human labour by automatically extracting data fields from incoming unstructured scanned documents.
The information to be automatically extracted from documents included handwritten text inside document scans and photos. Standard OCR solutions do not handle such inputs well.
The project objectives were to design and implement a POC solution, with the end goal of providing AXA with tangible numbers about what is realistically achievable with modern machine learning. This outcome would help AXA redesign AXA’s data collection and document processing workflows accordingly.
“
We have been looking for a provider for several months just to find out that standard data extraction solutions provided by well-known companies or startups don’t match our needs in terms of flexibility, costs or time to market. RARE Technologies came recommended to us because of their unique know-how, maturity of their solutions and impressive flexibility.

Ondřej Vich, AXA Digital strategy and Innovations leader.
THE SOLUTION
RARE chose to use deep learning for the solution. The final POC output was:
- Analysis of data types, variance and potential approaches based on data provided by AXA CZ.
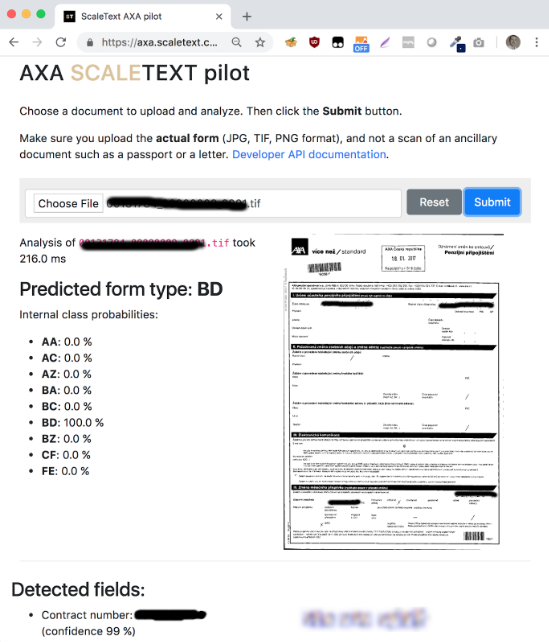
- Classification of incoming document forms (“What type of document is this and business unit is it meant for?”), using deep learning in Keras.
- Extraction of hand-printed field values (e.g. “Where in the document is the Contract Number, and what is its content?”) using Keras.
- A prototype web interface for uploading documents and immediately observing the analysis results.
- A REST API for calling the service programmatically at scale.
“
Since regional handwriting differs considerably from American handwriting (especially for handwritten digits), and the location of the fields is unknown to start with, standard existing data science algorithms and datasets such as MNIST were not useful. We had to build a fully tailored, custom deep learning solution specifically for AXA documents.

Dr. Radim Řehůřek, R&D Director, RARE Technologies
“RARE Technologies guided us through the pilot phase, implementing and explaining the potential approaches and then discussing implications of outcomes. This enabled us to easily challenge our original expectations and needs, and define the real benefits of machine learning within the environment of our insurance company.” Ondřej Vich, AXA Digital strategy and Innovations leader
THE RESULTS
The delivered system was able to model its detection uncertainty, either outputting the entire field (not a single character wrong) or saying “I don’t know” with over 96% accuracy.
