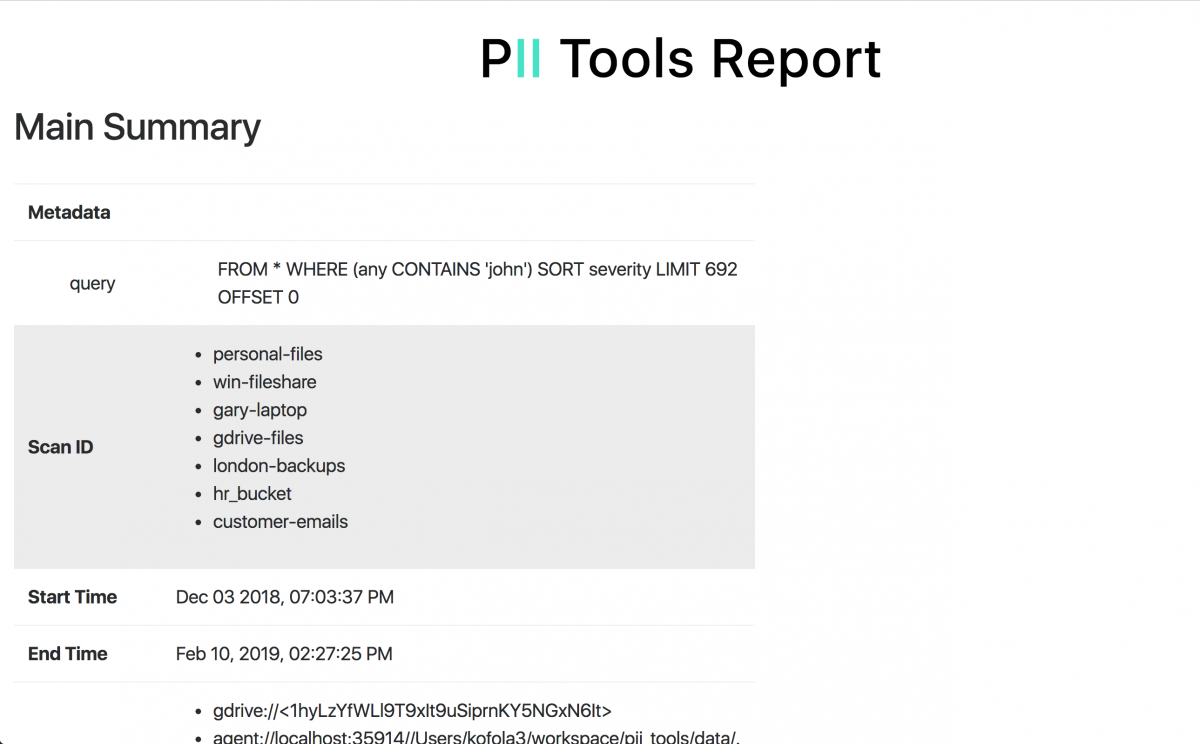
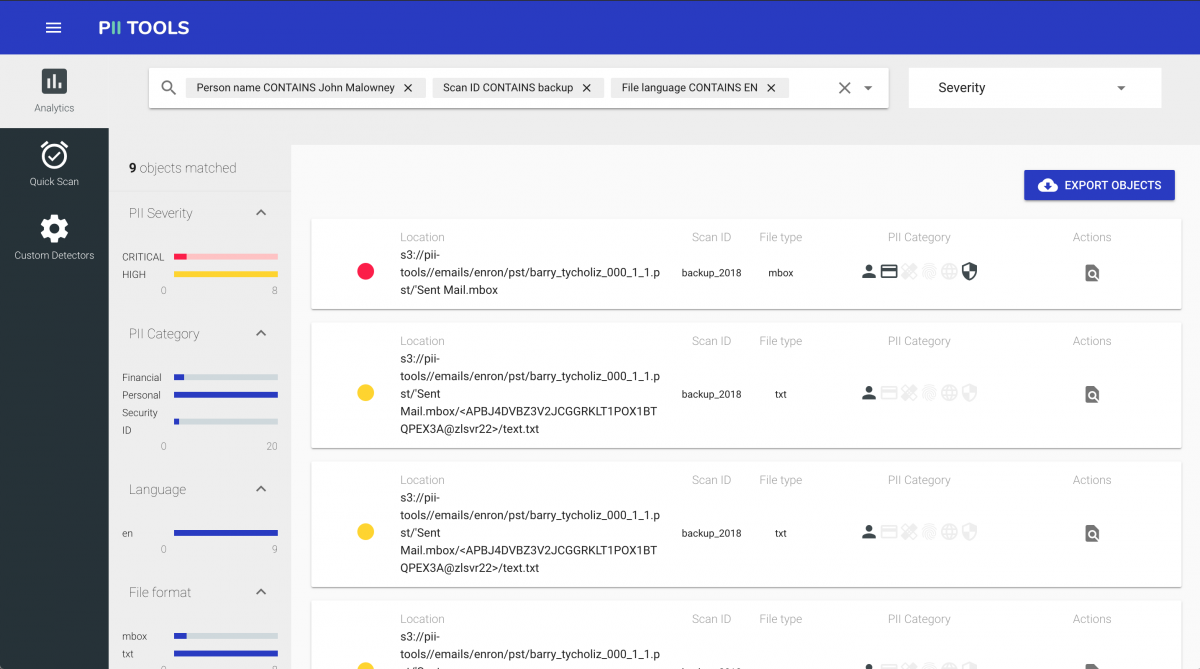
In the latest February release (version 2.4.0), we combined Personal Data Analytics search with dynamic HTML report generation to make GDPR compliance and auditing easier.
After PII Tools implemented scanning of on-prem Windows workstations, endpoints and file shares into PII Tools, the nr. 1 request has been to find personal, sensitive and intimate data inside Office 365 installations.
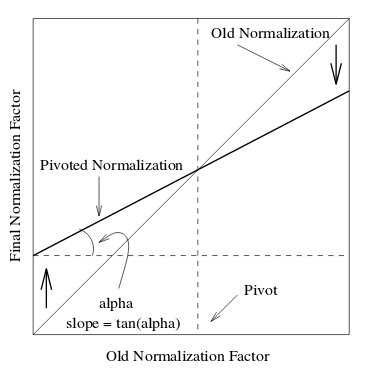
As a part of the RARE incubator program my goal was to add two new features on the existing TF-IDF model of Gensim. One was implementing a SMART information retrieval system (smartirs) scheme [1] and the other was implementing pivoted document length normalization [2].
Hi everyone, my name is Dmitry Berdov, I’m a graduate student at the Ural Federal University, now working in QA testing (automation) sphere. I had no experience with writing documentation before joining the RARE Incubator, where my task has been to refactor and improve the poor state of Gensim docs. Now, after several months of shooting myself hard in the ...
Last month, we ran a survey among Gensim users to get a better idea what delights and annoys you. The ~7 minute survey was completed by 448 people. That’s a great juicy sample, big thanks to all who participated! Full detailed statistics here; in this post I’ll summarize what we found and what it means for Gensim.
Episode Summary: Leo Boytsov, a PhD researcher from the Language Technologies Institute of Carnegie Mellon University, talks about fast approximate search in modern information retrieval. We discuss the curse of dimensionality, hard-to-beat baselines and NMSLIB, Leo's super fast library for nearest-neighbour search. How does NMSLIB compare to Facebook's FAISS and Spotify's Annoy? Warning: very technical. Links & resources: NMSLIB: Leonid's ...
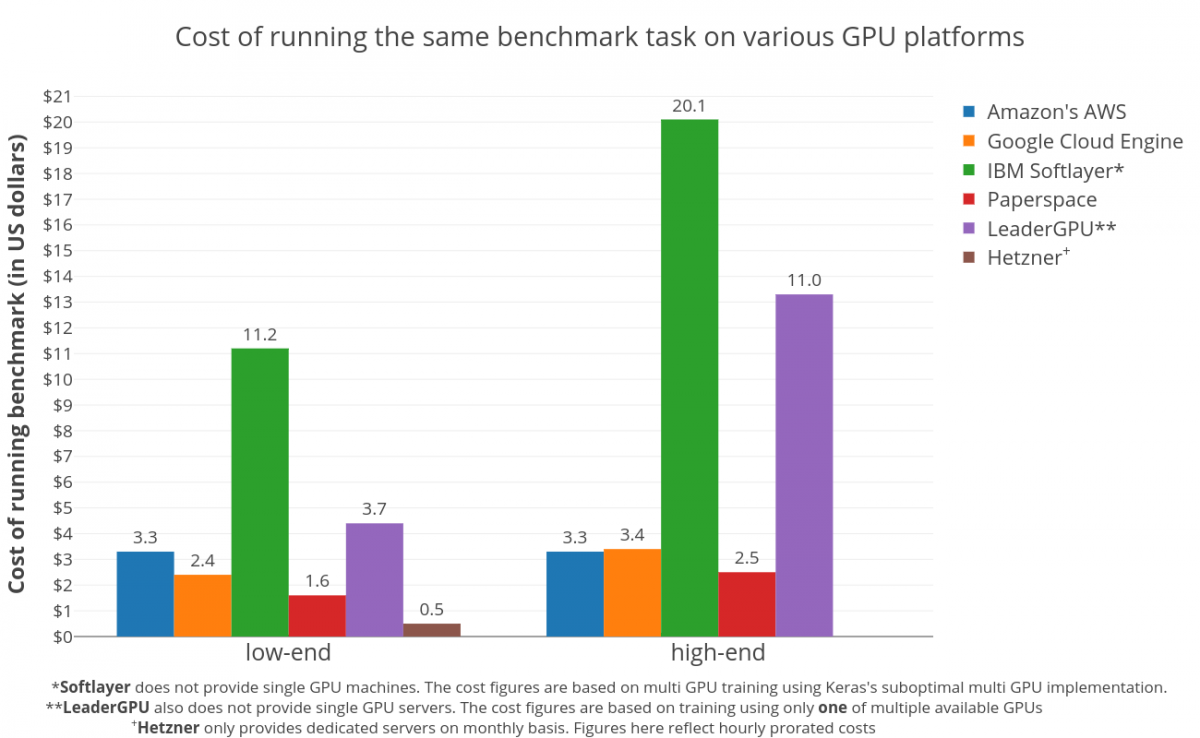
We had recently published a large-scale machine learning benchmark using word2vec, comparing several popular hardware providers and ML frameworks in pragmatic aspects such as their cost, ease of use, stability, scalability and performance. Since that benchmark only looked at the CPUs, we also ran an analogous ML benchmark focused on GPUs.
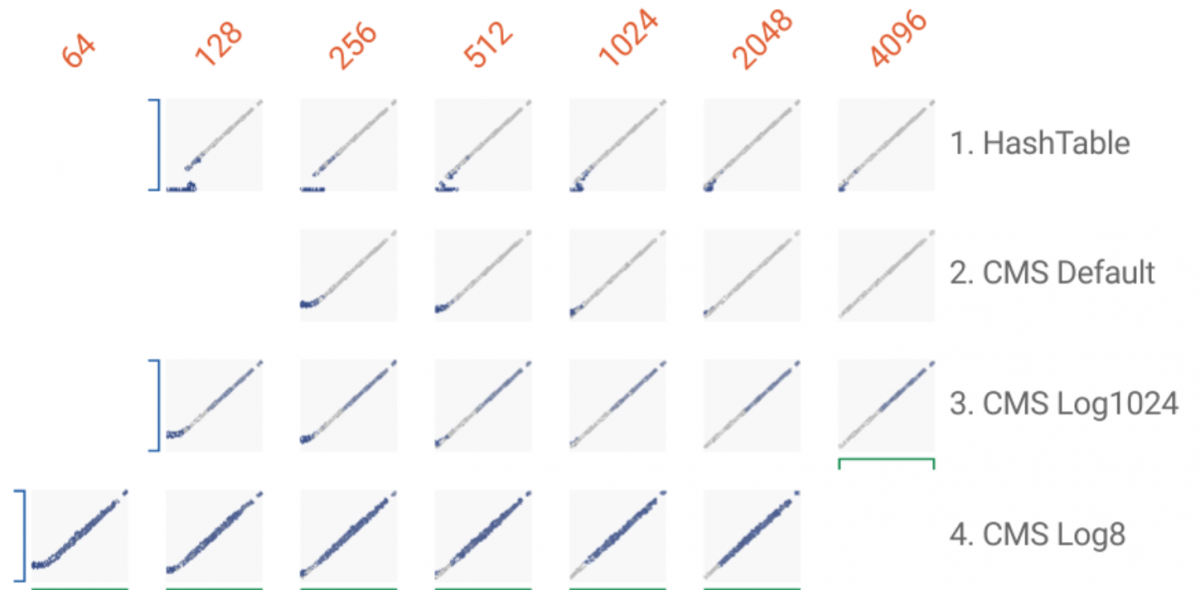
In my previous post on the new open source Python Bounter library we discussed how we can use its HashTable to quickly count approximate item frequencies in very large item sequences. Now we turn our attention to the second algorithm in Bounter, CountMinSketch (CMS), which is also optimized in C for top performance.
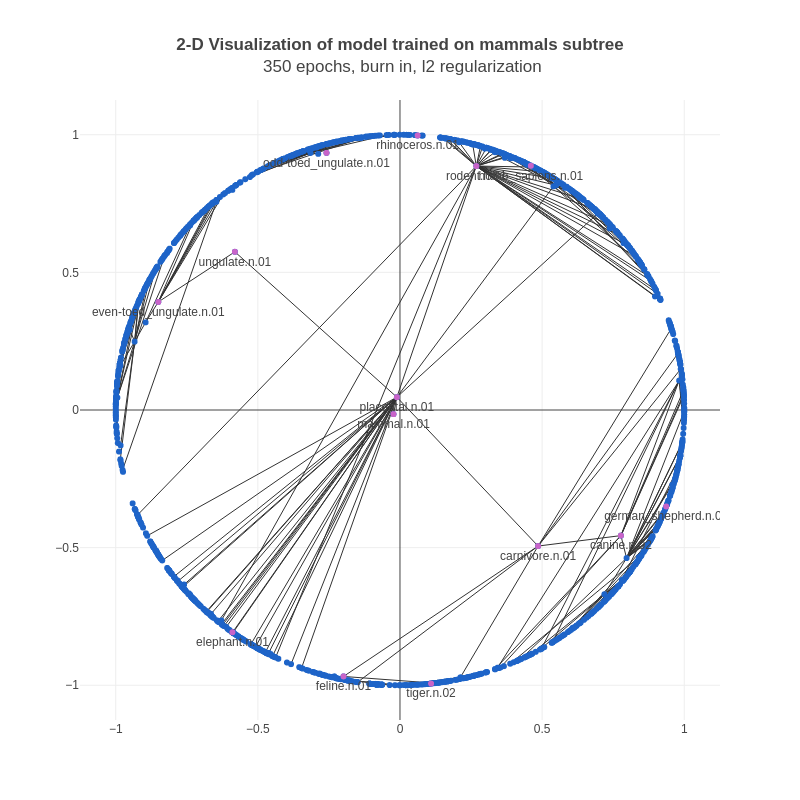
I have been working on implementing a model called Poincaré embeddings over the last month or so. The model is from an interesting paper by Facebook AI Research – Poincaré Embeddings for Learning Hierarchical Representations [1]. This post describes the model at a relatively high level of abstraction, and the detailed technical challenges faced in the process of implementing it.
 RARE Technologies
RARE Technologies