 RARE Technologies
RARE TechnologiesDeduplicating data for product search
Case study: Thermo Fisher Scientific
THE BUSINESS CHALLENGE
Thermo Fisher Scientific (TFS) is the world leading company in biotechnology product development, with revenues of more than $24 billion and 70,000 employees globally.
As part of optimizing its services, TFS is executing internal projects to improve product search for customers and web visitors, over the 1 million+ products inventory sold by TFS.
The objective of this collaboration was intelligent cleanup and deduplication of product data, to reduce the size of the product inventory plus enable new product search workflows.
“
RARE Technologies came recommended from our business network. I decided to go with RARE as our partner because of their successful track record and deep industry experience. Throughout the project, Radim and his team exceeded our expectations, delivering on time and budget with a refreshingly honest, no-nonsense approach.

Timothy Sendera, Senior Director of Information Science, Thermo Fisher Scientific
THE SOLUTION
The primary research challenge was to completely eliminate false positives so as to never cluster independent products together, while maximizing the amount of clustered product values to meet the objective of cleaning up the product inventory.
This is highly non-trivial because even a single-letter difference in a product attribute can imply completely different semantics, ruling out naive edit distance or vector embedding solutions.
Similarly, even the exact same value in different product categories can lead to different clustering decisions, resulting in multi-pronged algorithms that must depend on careful context analysis and NLP.
In addition, the delivered solution had to be packaged for non-technical end users (internal subject matter experts), putting additional constraints on UX and model deployment.
To meet these problem constraints, RARE executed a 2-phase approach:
1. R&D stage
RARE identified salient subproblems and designed algorithms for their solution, such as automatically identifying composite product values, meaningful word boundaries (tokenization) for medical and chemical data, linking collocations and multi-word expressions, domain-specific terminology and developing soft-similarity measures. RARE then combined these solutions into a final deduplication workflow, formulated as a constraint optimization search in a complex parameter space.
The final workflow combined automated deduplication with human decisions, for a semi-automated hybrid workflow. The algorithms made independent choices where possible, while inviting a human (a subject matter expert from TFS for the given product category) to step in for hard cases and make the decision manually.
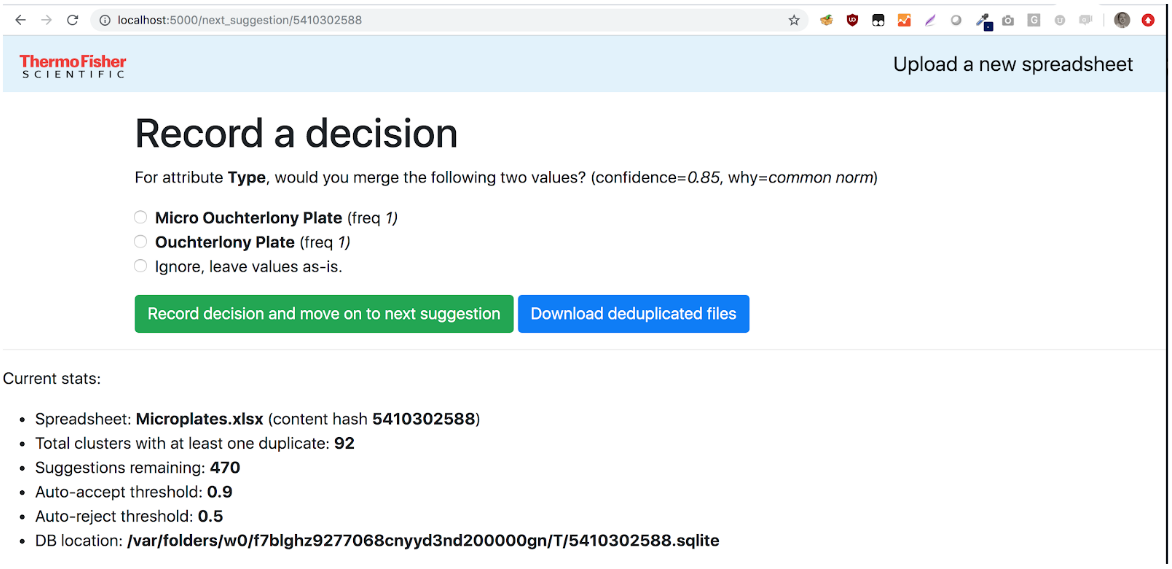
All algorithms were designed to track “why” they made a particular choice throughout the pipeline, to make their decisions explainable and assist the human experts in the semi-automated workflow.
2. Application development stage
Since the intended end users were non-technical subject matter experts, RARE was asked to also package the R&D solution from Stage 1 into an easy-to-use Windows application.
To meet this goal, RARE team developed an end-to-end web application: from uploading product data, to the semi-automated clustering, to producing the final deduplicated inventory on output. The web application used
This whole web application, including all machine learning models and other necessary data, was then packaged into a single .exe Windows file. By simply double-clicking this executable file, the SME end-users were able to work with the hybrid workflow directly on their own machines, in their local internet browser, without the need for any complex installations or application setup.
“
I really liked RARE’s iterative approach, from scoping to algorithm design to error analysis and quality evaluation. This was the key to the project success, converging on a successful solution in a matter of weeks instead of months.

Joe Bell, Digital Product Manager, Thermo Fisher Scientific
“The solution gave us a 200% increase in productivity, with 130 Subject Matter Export hours saved upfront plus an estimated 67% reduction in regular future maintenance. I look forward to working with Radim on our follow-up NLP projects to improve search and discovery.”
Clayton Nichols, Senior Business Analyst, Thermo Fisher Scientific
THE RESULTS
The streamlined, made-to-measure solution produced by RARE enabled TFS staff to quickly and reliably clean up their large product inventory. This significantly helped TFS in their long-term goal of boosting internal productivity by harmonizing the company data model, as well as improving product discovery for customers to generate extra revenue.
