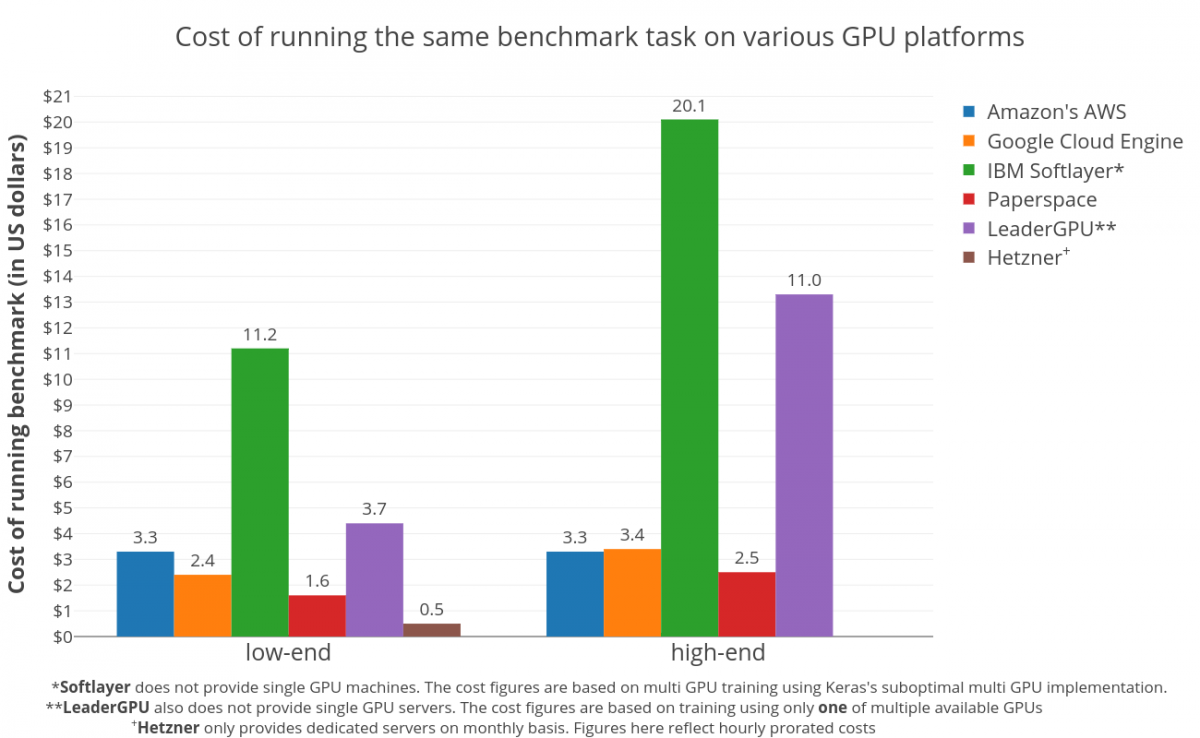
We had recently published a large-scale machine learning benchmark using word2vec, comparing several popular hardware providers and ML frameworks in pragmatic aspects such as their cost, ease of use, stability, scalability and performance. Since that benchmark only looked at the CPUs, we also ran an analogous ML benchmark focused on GPUs.
Some of our consulting tasks keep on repeating, hinting at a wide-spread pain point across our clients and industries. One of them is looking for meaningful nuggets of information in large unstructured document databases. How do you extract actionable insights and relationships from messy datasets, such as Customer Support records? How about financial reports, or job CVs? Are you still …
 RARE Technologies
RARE Technologies