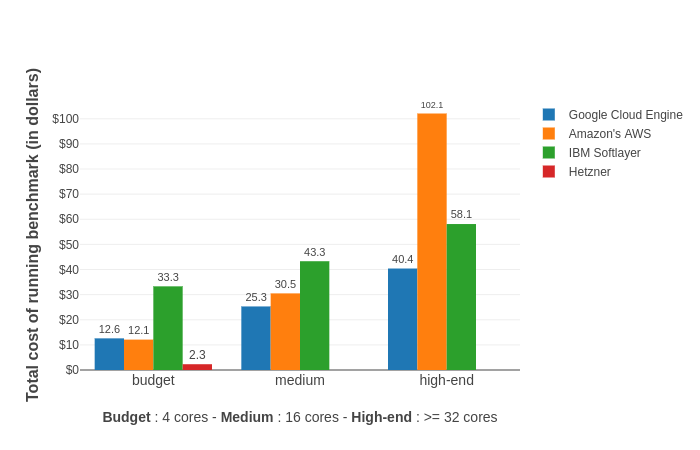
RARE Technologies
RARE Technologies
Docstrings in open source Python
Hi everyone, my name is Dmitry Berdov, I’m a graduate student at the Ural Federal University, now working in QA testing (automation) sphere. I had no experience with writing documentation before joining the RARE Incubator, where my task has been to refactor and improve the poor state of Gensim docs. Now, after several months of shooting myself hard in the ...