 RARE Technologies
RARE Technologies2nd September, 2017
The final blogpost in the GSoC 2017 series summarising all the work that I did this summer can be found here.
15st August, 2017
During the last two weeks, I had been working primarily on adding a Python implementation of Facebook Research’s Fasttext model to Gensim. I was also simultaneously working on completing the tasks left for adding scikit-learn API for Gensim models.
For adding unsupervised Fasttext in Gensim, I have created PR #1525. Initially, I had been going through the original C++ code for Fasttext and the paper Enriching Word Vectors with Subword Information to understand the model well before I started implementing it. Now, I have added code for both CBOW & skipgram modes and have also created unittests for checking the basic correctness of the two types of models. We plan to base our evaluation on how close the results given by our implementation are with those given by original Fasttext C++ code for tasks like suggesting the most similar words for the input word.
Regarding adding scikit-learn API for Gensim models, I refactored the existing code for sklearn API classes in PR #1473 by renaming transformer classes, removing unnecessary class methods, updating transform() method and adding examples in the IPython notebook for sklearn. This PR has now been merged. 🙂
I also updated the code added in PR #1462 as per the things discussed for PR #1473. This included renaming transformer classes, updating unittests and adding examples in the IPython notebook. Also, PR #1445 which adds score() function for LDA transformer for sklearn has now been merged.
1st August, 2017
In the last two weeks, I worked mainly on updating and adding sklearn API for models in Gensim and updating tests in shorttext. I was not able to add a blog in the previous week since my college semester has now commenced and I was travelling at the time.
In PR #1473, I removed the BaseTransformer class and refactored the code for other API classes accordingly. I updated the unittests to ensure the after calling set_params() and fit() function, the parameter values are set for the actual Gensim model as well. I also changed transform() function to use sparse2full() while creating the output matrix for the function. In the same PR, I added testConsistencyWithGensimModel() unittest for LDA and Word2Vec transformers. In PR #1462, I added API classes for Gensim’s Hdp and Phrases models along with the corresponding unittests. In PR 1445, I updated the example for score() function for LDA model in the IPython notebook sklearn_wrapper.ipynb.
In shorttext, I added PR #15 for restructuring the tests. I also created PR #16 for updating the documentation in docs.tutorial_nnlib. In PR #18, I modified the test conditions to make sure tests pass for all valid scenarios.
18th July, 2017
During the last week, I continued to work on my PRs in both shorttext and Gensim repositories.
In Gensim, I worked on PR #1445 to fix error handling in the function topic_coherence.direct_confirmation_measure in case a top-n topic word for the training corpus is not present in the corpus being used to compute the topic-coherence value. I also added examples in docs.notebooks.sklearn_wrapper.ipynb for various scoring function modes for LdaModel’s API class. I continued to work on PR #1473 to refactor the exising code after removing functions get_params(), set_params() and partial_fit() from the base API class. As part of PR #1462, I added code and unitests for Text-to-BOW and Tf-Idf models in Gensim.

In shorttext, I created PR #12 to integrate the repository with Travis CI. So, we can now add unittests to make sure new code changes don’t break the functioning of the existing code (yay!). I also created PR #13 to add unittests for the classes CNNWordEmbed, DoubleCNNWordEmbed and CLSTMWordEmbed present in classifiers.embed.frameworks.
11th July, 2017
In the last week, I worked on PRs in both Gensim and shorttext repositories.
In Gensim, I worked on PR #1445 to include u_mass mode in the score function for SklLdaModel class. I also updated the IPython notebook for scikit-learn integration with examples to explain the usage of the newly added code. In addition to this, I worked on adding a scikit-learn wrapper for Gensim’s Doc2Vec class in PR #1462. The same PR also adds unittests for the new wrapper class. I also created PR #1473 to refactor the code for all the existing sklearn-api classes. This refactoring included renaming wrapper classes, updating unittests, rephrasing docstrings and updating corresponding IPython notebook examples.
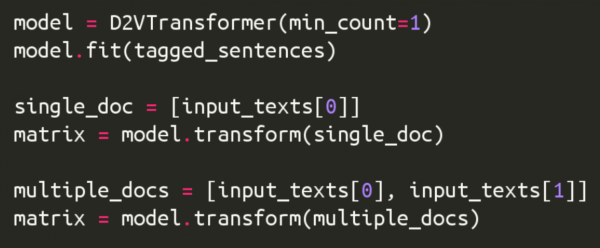
The changes that I made to shorttext during the last week were primarily focused around adding support for the changes made in PR #1248 in Gensim. Regarding this, I worked on PR #9 which fixed a bug in the code to load the value of with_gensim variable from the saved json file and also updated docstrings for the save and load functions for VarNNEmbeddedVecClassifier class. I also created PR #10 which added support for the changes made in PR #1248 by adding the codepath along the case when with_gensim=True to the classes DoubleCNNWordEmbed and CLSTMWordEmbed in classifiers.embed.nnlib.frameworks.
4th July, 2017
During the previous week, I mainly worked on PR #1201, PR #1437 and PR #1445.
I was finally able to get PR #1201 merged after obtaining the relevant benchmark values to analyze the effect on the time required for training a Word2Vec model due to the loss-computation code added in the pull-request.
 In this week, a large chunk of my time and effort was devoted to working on PR #1445, which implements score function for the scikit-learn wrapper class for LDA model. The perplexity mode of the function has been implemented and I am currently working on how to implement other modes (i.e. c_v, c_uci, c_npmi and u_mass) which use topic-coherence as a measure for computing the score value. However, as of now, there are certain issues with the implementation of these 4 modes. For the sliding-window based modes i.e. c_v, c_uci and c_npmi, we need Texts parameter of the class CoherenceModel in order to compute the topic-coherence values. However, this parameter is not needed as such for the LDA model’s sklearn wrapper so we are having to input extra information just for implementing the score function associated with the class, which is not a desirable scenario. For u_mass mode of computing topic-coherence, I am getting a ZeroDivisionError because of w_star_count value being zero in this line, which computes the pointwise mutual information between word-pairs formed from the top-n words representing the topics. The reason for this is the fact that count of words, which represent the topics obtained for training data, may be zero in the testing data. A solution for both these issues is adding an additional optional attribute to the wrapper class for LDA model so that the user can store the value of Texts and pass it to the score function. However, this solution has not been finalized till now and the implementation details of this PR are still being discussed.
In this week, a large chunk of my time and effort was devoted to working on PR #1445, which implements score function for the scikit-learn wrapper class for LDA model. The perplexity mode of the function has been implemented and I am currently working on how to implement other modes (i.e. c_v, c_uci, c_npmi and u_mass) which use topic-coherence as a measure for computing the score value. However, as of now, there are certain issues with the implementation of these 4 modes. For the sliding-window based modes i.e. c_v, c_uci and c_npmi, we need Texts parameter of the class CoherenceModel in order to compute the topic-coherence values. However, this parameter is not needed as such for the LDA model’s sklearn wrapper so we are having to input extra information just for implementing the score function associated with the class, which is not a desirable scenario. For u_mass mode of computing topic-coherence, I am getting a ZeroDivisionError because of w_star_count value being zero in this line, which computes the pointwise mutual information between word-pairs formed from the top-n words representing the topics. The reason for this is the fact that count of words, which represent the topics obtained for training data, may be zero in the testing data. A solution for both these issues is adding an additional optional attribute to the wrapper class for LDA model so that the user can store the value of Texts and pass it to the score function. However, this solution has not been finalized till now and the implementation details of this PR are still being discussed.
PR #1437, which adds scikit-learn API for Word2Vec model, has also been accepted and merged now. Right now, I am also working on PR #1462 which would be adding the scikit-learn API for the remaining Gensim models. I am currently working on Gensim’s Doc2Vec model in this PR.
In the coming week, I plan to complete the sklearn-wrapper implementation of Doc2Vec, Text to Bag-of-words and Topic-Coherence models in PR #1462. I also plan to wrap-up PR #1445 by resolving the above-discussed issues.
27th June, 2017
This week, I worked on creating new scikit-learn wrappers for Gensim models. In addition to that, I worked further on older unmerged PRs like PR #1201 and PR #7.
I created PR #1437 which adds an sklearn wrapper for Gensim’s Word2Vec model along with relevant unit-tests. Except a few minor suggestions which need to be incorporated in the code, the PR is merge-ready. I also worked further on PR #1403 which adds an sklearn wrapper for Gensim’s Author-Topic model. Some unit-tests like integration with sklearn Pipeline were earlier missing from the PR and this has now been merged.
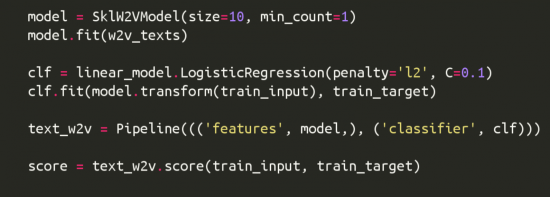
For PR #1201, the ongoing confusion about the apparent difference in training loss values obtained from Python and Cython paths got resolved after further discussion and I am currently working on adding useful benchmarks for the PR so that we get a clear idea about the effect on training time due to this code modification.
In shorttext, PR #7, which incorporates the change corrsponding to PR #1248 in Gensim, has now been merged. However, some changes corresponding to saving and loading of models still need to be implemented which I plan to complete in the coming week.
I am also currently working on PR #1445 which creates scorer functions for sklearn wrappers for models such as LDA, LSI etc so that the user doesn’t need to write a custom scoring function for tasks like GridSearch in scikit-learn.
In the coming week, I would be working on creating sklearn wrappers for Doc2Vec, Text to Bag-of-words and Tf-Idf models in Gensim. I also plan to finish the work left in PR #1201 and get it merged soon. 🙂
20th June, 2017
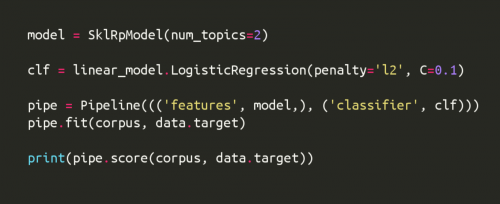
During the last week, I continued working on creating scikit-learn wrappers for Gensim’s LDA (PR #1398), LSI (PR #1398), RandomProjections (PR #1395) and LDASeq (PR #1405) models. After making several changes including updating wrapper class-methods and adding unit-tests for features like model persistence, integration with sklearn’s Pipeline, incorporating NotFittedError as well as fixing some of the older unit-tests, these PRs have now been accepted and merged. 🙂 I also created PR #1428, which updates the IPython notebook sklearn_wrapper.ipynb explaining the usage of sklearn wrappers for the four Gensim models mentioned above.
 I also worked further on PR #7 in shorttext by refactoring the code to reduce redundancy by getting rid of unnecessary files and classes. I am now working on updating the load and save methods associated with the modified classes.
I also worked further on PR #7 in shorttext by refactoring the code to reduce redundancy by getting rid of unnecessary files and classes. I am now working on updating the load and save methods associated with the modified classes.
In the last week, I had added Python and Cython code for computation of training loss for PR #1201. However, I have been getting different values of training loss when the code uses Python path and when it uses Cython path for the exact same input while training. I am currently investigating the reason for this difference in values. Once I have this figured out, I plan to get some useful benchmarks to see the effect of the newly added code.
During the last week, I had to devote more time for the existing wrappers than I had anticipated so I couldn’t get started with working on newer wrappers. So in the coming week, I would be creating scikit-learn wrappers for Word2Vec, Doc2Vec and Text to Bag-of-words models in Gensim. I also plan to finish the remaining work in PR #1201 and PR #7 in the following week.
13th June, 2017
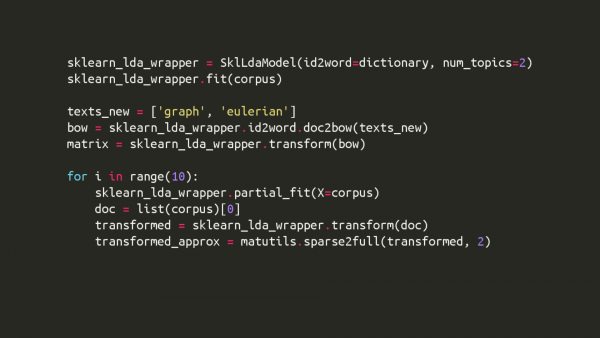
This week, I worked on developing scikit-learn wrappers for Gensim’s Random Projections (PR #1395), LDASeq (PR #1405) and Author Topic (PR #1403) models. I also refactored the existing scikit-learn wrappers for LDA and LSI models in PR #1398 by incorporating changes such as using composite design pattern, removing unnecessary attributes and updating the associated unit-tests.
Apart from this, I worked on PR #1201 which computes the training loss for Gensim’s Word2Vec model. For doing this, I needed to add code for computing the training loss in both Python and Cython code associated with the Word2Vec model. I am now working on getting useful benchmarks about the change in performance with-respect-to the time taken and memory used, as a result of the newly added code for training loss computation.
As mentioned in the last blogpost, I have also opened PR #7 for incorporating the changes made in Gensim in PR #1248 in shorttext’s existing code. This PR is a work in progress and I hope to wrap it up within this week.
In the coming week, I plan to develop scikit-learn wrappers for Gensim’s Word2Vec, Doc2Vec, Text to Bag-of-words and Tf-Idf models. I am also aiming to wrap up PR #1201 and PR #7 in the coming week.
6th June, 2017
We are into the second week of GSoC coding period and with regular commits and daily meetings, things seem to be in flow now. I have started working on the integration of Gensim with scikit-learn which would be the first phase of my GSoC work.
In the past, I had worked on PR #1244 which created a scikit-learn wrapper for Gensim’s LSI model. Also, we already had a scikit-learn wrapper for the LDA model (courtesy of PR #932). During the last week I worked on modifying LDA model’s code (PR #1389) and the associated sklearn wrapper’s code (PR #1382) slightly. Also, to avoid duplication of code in the wrappers, I also created the abstract class BaseSklearnWrapper in PR #1383. I also refactored the code for the existing sklearn wrappers for LDA and LSI models to incorporate this new class. In the same PR, I also fixed the set_params() function by using setattr() and also added unit-tests so that the issue doesn’t go unnoticed in the future.
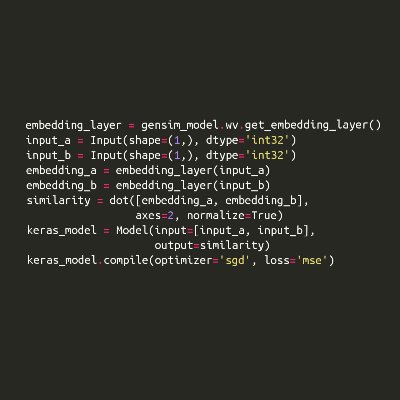
Apart from this, nearly two months and 41 commits later (phew!), I finally managed to wrap up PR #1248 which enables one to use Gensim’s Word2Vec model with Keras. Now that this PR has been merged in Gensim’s codebase, I would be incorporating this in shorttext’s code as well. The feedback that I have received for this PR has helped me learn many things about good coding practices as well as about technical writing in general. Hopefully, this is going to be useful in the future as well. 🙂
In the coming week, I plan to complete sklearn wrappers for Random Projections model, Author-Topic model and LDA Seq model. Plus, I also aim to wrap up PR #1201 which has been open for some time now.
30th May, 2017
This is my first post as part of Google Summer of Code 2017 working with Gensim. I would be working on the project ‘Gensim integration with scikit-learn and Keras‘ this summer.
I stumbled upon Gensim while working on a project which utilized the Word2Vec model. I was looking for a functionality to suggest words semantically similar to the given input word and Gensim’s similar_by_word function did it for me! After this, I started to dig into Gensim’s codebase further and found the library to be slick, robust and well-documented. When I came to know that Gensim was participating in GSoC 2017, I was stoked as I believed this was a chance for me to impactfully use my background with Natural Language Processing and Machine Learning by contributing to and improving a popular library like Gensim. In the past, I have undertaken some relevant coursework which includes courses like Deep Learning, Machine Learning and Information Retrieval to name a few. These courses not only helped me to get a strong theoretical understanding of the domains of NLP and ML in general but the associated lab components also gave me hands-on development experience to work on a real-world task. As a sophomore, I was also an intern at the Language Technologies Research Center at International Institute of Information Technology, Hyderabad where I worked on developing an open-domain question-answering system using deep learning.
My first substantial contribution to Gensim was PR #1207. The PR helped to ensure that a Word2Vec model could be trained again if the function _minimize_model did not actually modify the model. After this, I worked on PR #1209 which fixed issue #863. This PR added a function predict_output_word to Word2Vec class which gave the probability distribution of the central word given the context words as input. Another task that I worked on was issue #1082 which was resolved in PR #1327. The PR fixed the backward-incompatibility arising because of the attribute random_state added to LDA model in the Gensim’s 0.13.2 version.
Apart from this, I have already worked to some extent on the integration of Gensim with scikit-learn and Keras in PR #1244 and PR #1248 respectively. In PR #1244, I worked on adding a scikit-learn wrapper for Gensim’s LSI (Latent Semantic Indexing) Model. This enabled us to use “sklearn-like” API for Gensim’s LSI Model using functions like fit, transform, partial_fit, get_params and set_params. PR #1248 added a function get_embedding_layer to Gensim’s KeyedVectors class which simplified incorporating a pre-trained Word2Vec model in one’s Keras model. Hopefully, the learnings from both these pull-requests would be helpful while coding up the wrappers for the remaining models as well. Currently, I am working towards wrapping up PR #1201 which enables one to keep track of the training loss for Word2Vec model.
All these previous contributions to Gensim have helped me immensely in getting comfortable with Gensim’s codebase as well as the community’s coding standards and practices.
Gensim is a Python library for topic modeling, document indexing and similarity retrieval with large corpora. The package is designed mainly for unsupervised learning tasks and thus, to usefully apply it to a real business problem, the output generated by Gensim models should go to a supervised learning system. Presently, the most popular choices for supervised learning libraries are scikit-learn (for simpler data analysis) and Keras (for artificial neural networks). The objective of my project is to create wrappers around all Gensim models to seamlessly integrate Gensim with these libraries. You could take a look at my detailed proposal here.
This work would be a joint project with the shorttext package. shorttext is a collection of algorithms for multi-class classification for short texts using Python. shorttext already has scikit-learn wrappers for some of Gensim’s models such as Latent Dirichlet Allocation model, Latent Semantic Analysis model and Random Projections model. Similarly, shorttext also has wrapper implementations for integration of various neural network algorithms in Keras with Gensim. However, there are certain differences in the implementation of the Keras wrappers in shorttext with the implementation planned in Gensim. For instance, for the wrapper of any Gensim model using KeyedVectors class, shorttext uses a matrix for converting the training input data into a format suitable for training the neural network (see here), while Gensim would be using a Keras Embedding layer. This not just simplifies the way in which we create our Keras model (simply create the first layer of the model as the Keras Embedding layer and then the remaining Keras model) but also uses less memory since we are not using any extra matrix. In any case, we can take several cues from the wrappers implemented in shorttext while developing wrappers in Gensim as well. So, a big shout-out to Stephen for creating this useful package! 🙂
I would like to thank Radim, Lev, Stephen, Ivan and Gordon who have all helped me tremendously to learn and improve through their valuable suggestions and feedback. The Gensim community has been really forthcoming right from the start and on several occasions, I have been guided in the right direction by the members. I am exhilarated to be working with Gensim and I really hope that the work that I do this summer would be useful for Gensim users.
