 RARE Technologies
RARE TechnologiesHi everyone, my name is Dmitry Berdov, I’m a graduate student at the Ural Federal University, now working in QA testing (automation) sphere. I had no experience with writing documentation before joining the RARE Incubator, where my task has been to refactor and improve the poor state of Gensim docs. Now, after several months of shooting myself hard in the foot, I would like to share my insights from this unforgettable process.
This article can be useful if you are going to write documentation for open source projects. We will talk about the most common mistakes made by beginners.
Before we start, let’s discuss one question:
0) Why should you try this?
Interesting fact: code documentation can be more important than new functionality! The reason is that users can’t use the latest features, if they don’t understand basic product possibilities. Furthermore, useful docstrings (documentation strings used in Python APIs) build users' loyalty.
It is also vital to note that good documentation is impossible without a good understanding of the code. Thereby, writing docstrings leads to improved insight into the project, your efforts will help new users get settled, this activity broadens your mind. Some useful introductory information can be found here; read this before you begin to write docstrings:
- Numpy docstring documentation https://github.com/numpy/numpy/blob/master/doc/HOWTO_DOCUMENT.rst.txt
- More examples of docstrings http://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_numpy.html
- Sphinx-Napoleon reference https://media.readthedocs.org/pdf/sphinxcontrib-napoleon/latest/sphinxcontrib-napoleon.pdf
Now you are ready.
1) Be attentive. Do not surprise the user.

Do not do this, please.
Sometimes even minor single typo has a critical impact on documentation clarity (especially in complex objects). Next example shows the common structure of docstrings for a single method:
def arithmetic_mean(confirmed_measures):
"""
# A short method description, 1-2 sentences, written in imperative mode.
Perform arithmetic mean aggregation on output obtained from
the confirmation measure module.
Parameters
----------
confirmed_measures : list of float # format (param : type)
List of calculated confirmation measure on each set in the segmented topics.
Returns
-------
`numpy.float` # format (type)
Arithmetic mean of all the values contained in confirmation measures.
Examples
--------
>>> from gensim.topic_coherence.aggregation import arithmetic_mean
>>> arithmetic_mean([1.1, 2.2, 3.3, 4.4])
2.75
"""
return np.mean(confirmed_measures)
2) Brevity is the soul of wit*
*Unless it is Hilbert's twelfth problem, of course.
Good docstring strike a balance between a minimal word usage and an exhaustive description. Simple functions may have no docstrings at all, while complicated one should be thoroughly outlined.
# A simple method, it is understandable without any docstrings.
def sum_integers(a, b):
return a + b
# Here, your soul shall suffer without documentation!
class LsiModel(interfaces.TransformationABC, basemodel.BaseTopicModel):
"""
Model for `Latent Semantic Indexing`_.
Decomposition alagorithm is in `"Fast and Faster: A Comparison of Two Streamed
Matrix Decomposition Algorithms"`_.
Parameters
-----
* :attr:`gensim.models.lsimodel.LsiModel.projection.u` - left singular vectors,
* :attr:`gensim.models.lsimodel.LsiModel.projection.s` - singular values,
* ``model[training_corpus]`` - right singular vectors (can be reconstructed if needed).
Notes
--------
`FAQ about LSI matrices`_.
Examples
--------
>>> from gensim.test.utils import common_corpus, common_dictionary
>>> from gensim.models import LsiModel
>>>
>>> model = LsiModel(common_corpus[:3], id2word=common_dictionary) # train LSI model
>>> vector = model[common_corpus[4]] # apply LSI model to a new bag-of-words document
>>> model.add_documents(common_corpus[4:]) # update LSI model with new documents
>>> model.save("lsi.model") # save model
>>> loaded_model = LsiModel.load("lsi.model") # load back the saved LSI model
"""
def __init__(self, corpus=None, num_topics=200, id2word=None, chunksize=20000,
decay=1.0, distributed=False, onepass=True,
power_iters=P2_EXTRA_ITERS, extra_samples=P2_EXTRA_DIMS, dtype=np.float64):
"""Construct an `LsiModel` object.
`corpus` or `corpus` + `id2word` must be supplied in order to train the model.
Parameters
----------
corpus : {iterable of list of (int, float), scipy.sparse.csc}, optional
Stream of document vectors or sparse matrix of shape (`num_terms`, `num_documents`).
num_topics : int, optional
Number of requested factors (latent dimensions)
id2word : dict of {int: str}, optional
ID to word mapping, optional.
chunksize : int, optional
Number of documents to be used in each training chunk.
decay : float, optional
Weight of existing observations relatively to new ones.
distributed : bool, optional
If True - distributed mode (parallel execution on several machines) will be used.
onepass : bool, optional
Whether the one-pass algorithm should be used for training.
Pass `False` to force a multi-pass stochastic algorithm.
power_iters: int, optional
Number of power iteration steps to be used.
Increasing the number of power iterations improves accuracy, but lowers performance
extra_samples : int, optional
Extra samples to be used besides the rank `k`. Can improve accuracy.
dtype : type, optional
Enforces a type for elements of the decomposed matrix.
"""
As we can see, the class docstring contains an overall description with links to external sources. The parameters section is for parameters descriptions, notes are used for helpful external additions, and examples has a simple usage demonstration. Methods are described in the same way. I strongly recommend you to read this article: https://github.com/numpy/numpy/blob/master/doc/HOWTO_DOCUMENT.rst.txt.
3) An example is worth a thousand words
A good example can help the user see non-obvious details, to "grok" the class or method purpose and more efficiently than by huge text description. Don’t be afraid to add a comment to every example if necessary. Usually it's enough to cover just the basic functionality, but for maximum coverage some methods may need 2 or even more examples - this is OK. This article can help you gain insight into this subtheme: http://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_numpy.html.
def add_vocab(self, sentences):
"""
Update model with new `sentences`.
Parameters
----------
sentences : iterable of list of str
Text corpus to update the model with.
Example
-------
>>> from gensim.test.utils import datapath
>>> from gensim.models.word2vec import Text8Corpus
>>> from gensim.models.phrases import Phrases
>>>
>>> # Create corpus and use it for phrase detector
>>> sentences = Text8Corpus(datapath('testcorpus.txt'))
>>> phrases = Phrases(sentences) # train the collocation model
>>> assert len(phrases.vocab) == 37
>>>
>>> more_sentences = [
... [u'the', u'mayor', u'of', u'new', u'york', u'was', u'there'],
... [u'machine', u'learning', u'can', u'be', u'new', u'york' , u'sometimes']
... ]
>>>
>>> phrases.add_vocab(more_sentences) # add new sentences to model
>>> assert len(phrases.vocab) == 60
"""
To conclude the process, always launch documentation tests (doctests in Python) python -m doctest path/to/your/file.py when your job is done.
4) “Find usages in the project itself”: discover the answer to your question
This fact is not so evident, but you really can figure out so much different data (object's description, examples of usage, etc) from unit tests, developers’ comments and source articles. Use it when you have a lack of information.
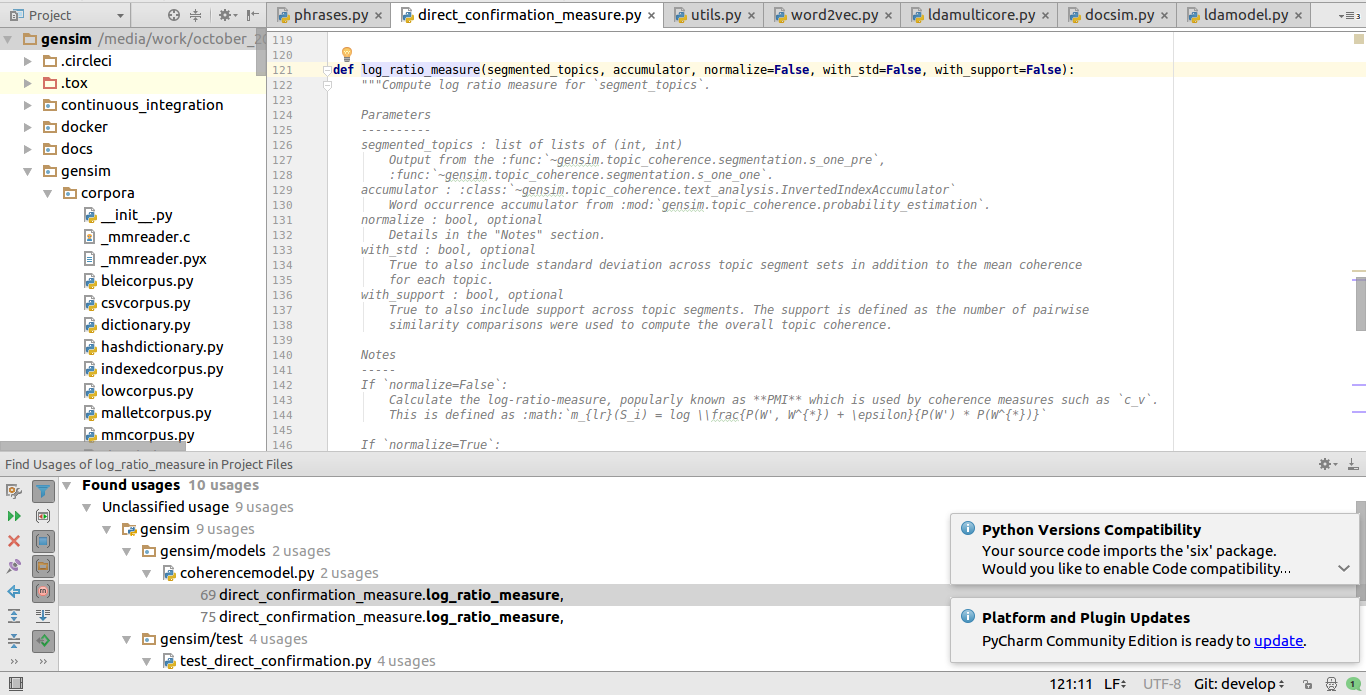
Search example.
If that doesn’t help, using git blame and asking the code author is your best bet. The git blame command can be used to determine when a certain change was made. For example, the command
$ git blame gensim/models/phrases.py -L 228,238 will show a hash indicating which commit last changed the lines 228-238 in the phrases.py file.
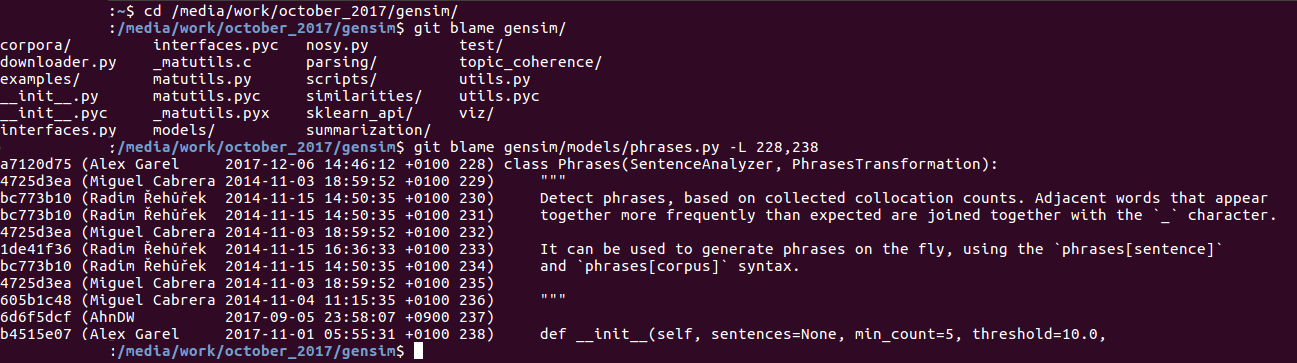
Git Blame example.
The unit tests for Gensim are located in https://github.com/RaRe-Technologies/gensim/tree/develop/gensim/test.
5) Beware of LaTeX + Sphinx
No, they won’t kill you. But they are gonna hurt you really really bad. As it turned out, the LaTeX module installation comes with some non-obvious problems, and that’s why creating LaTeX formulas in docstrings didn’t work. Some users (especially MAC owners) couldn’t build the documentation at all!
If you have this problem, try to create the documentation in CircleCI (right in the Pull Request go to TravisCI - you should be logged in it - then click on “Artifacts”) directly, and take a screenshot for further use in the project.
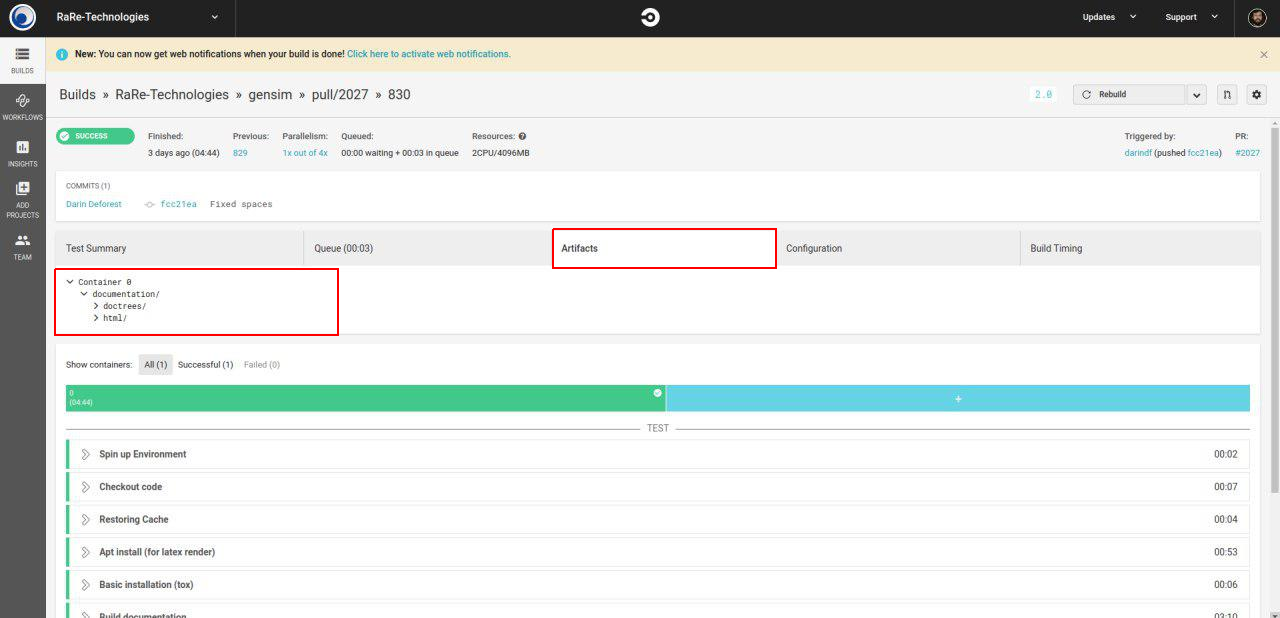
Creating documentation.
What about Sphinx? It comes with some "strangeness" too. String enumeration makes error search a bit tougher. Also sometimes binary search can be a good idea.
6) Time planning matters
Of course, some students work like “Situation is under control, I still have the whole night before the deadline!”. But this approach increases the number of possible mistakes. My experience shows that the best way to work with the Incubator is every day, at least 1 hour per day.
Push commits every day.
In conclusion
There is no doubt that docstrings are a vital tool that helps everybody: users benefit from an easier way to understand the software, while the docstring creator comes out with an improved knowledge of the project.
Finally, I would like to express my gratitude to RARE Technologies for possibility to participate in Incubator program and to my mentor Menshikh Ivan. During the Gensim Incubator I was working on refactoring the documentation for multiple modules (phrases, topic_coherence, etc.; see PRs #1950, #1933, #1910, #1835, #1814, #1714, #1684). I've had an unforgettable experience, which will help me in my future IT adventures.
