RARE Technologies
RARE Technologies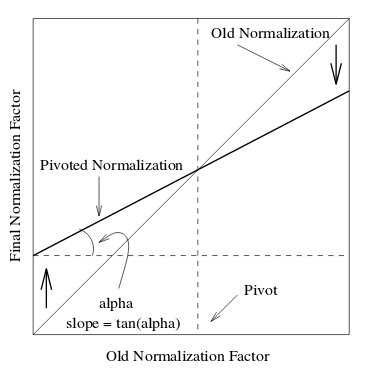
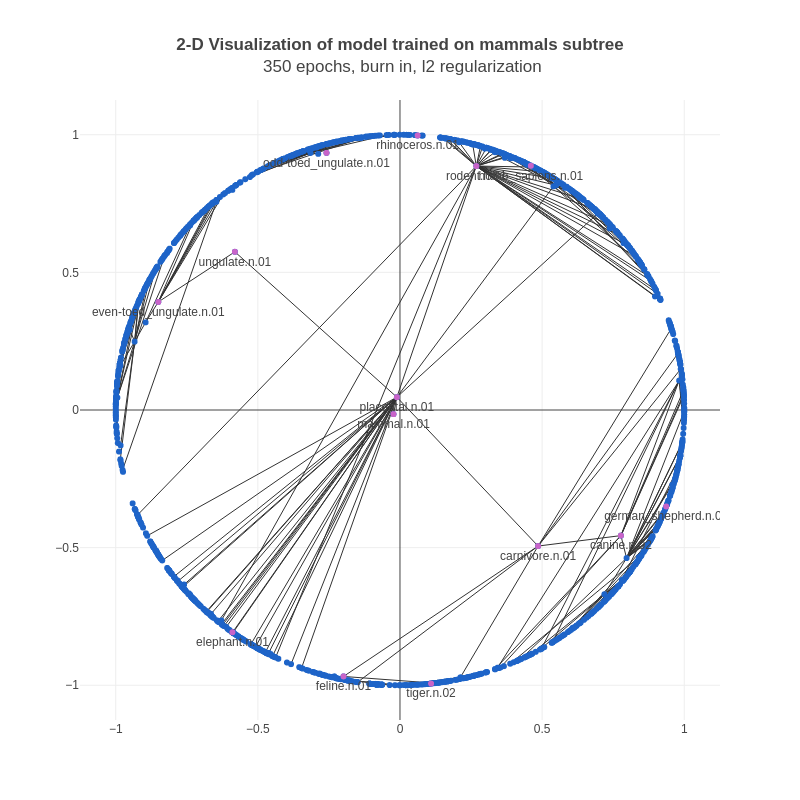
Pivoted document length normalisation
As a part of the RARE incubator program my goal was to add two new features on the existing TF-IDF model of Gensim. One was implementing a SMART information retrieval system (smartirs) scheme [1] and the other was implementing pivoted document length normalization [2].