 RARE Technologies
RARE TechnologiesAround a month into GSoC and into coding Dynamic Topic Models, there have been many challenges and experiences along the way.
Before getting into the problems I faced, I’ll briefly describe what Dynamic Topic Models are. It would be helpful to read my previous blog post where I described Topic Models, first. You can also just do a quick google search of Topic Modeling to get up to speed.
So, in Dynamic Topic Models we concern ourselves with the evolution of topics. This means that if we divide our corpus into different time-frames which they belong in, a topic ‘evolves’ from it’s previous time-frame. What does this mean? Let’s revisit our Harry Potter example from the previous blog post.
A Dynamic Topic Model (DTM, from henceforth) needs us to specify the time-frames. Since there are 7 HP books, let us conveniently create 7 timeslices, one for each book. So each book contains a certain number of chapters, which are our documents in our example.
We called one of our topics The Voldemort Topic. It (hypothetically) contained the following keywords –
“Voldemort, Death, Horcrux, Snake, Dark…”.
In a DTM, the words in a topic are fit in the first timeslice, after which they evolve. The first timeslice for us is Harry Potter and the Philosopher’s Stone, where our Voldemort Topic is not likely going to contain the words Horcrux, or Snake.
In fact, the Voldemort Topic is more likely going to contain words more like –
“Voldemort, Quirrell, Philosopher’s, Evil..”.
In our second time-slice, you can expect Quirrell to make way for something likeChamber. So, maybe, if we actually ran DTM on the HP corpus (Note to self: Run DTM on the Harry Potter books when you get the time!), we might see the Voldemort Topic evolve like this, over the 7 books:
- Voldemort, Quirrell, Philosopher’s, Evil, …
- Voldemort, Chamber, Basilisk, Petrified, …
- Death, Voldemort, Servant, Pettigrew, ..
- Voldemort, Goblet, Return, Death, ..
- Voldemort, Return, Death, Nagini, …
- Voldemort, Horcrux, Death, …
- Voldemort, Death, Hallows, Hogwarts, ..
So what can we understand from the above evolution? While the key ‘theme’ of a topic and it’s keywords are more or less the same, depending on the documents in that timeslice, they change. The Blei DTM paper is a good way to learn more about how it works, but an even better way is to see it in action: This is a Gensim DTM tutorial I contributed to which walks one through the process of setting up DTM on your own machine, and how to make sense of the results.
If you didn’t really understand what’s going on in the topic evolution (or haven’t read Harry Potter), this image from Blei’s paper gives a nice example of Topic Evolution in research papers, particularly Atomic Physics and Neuroscience.
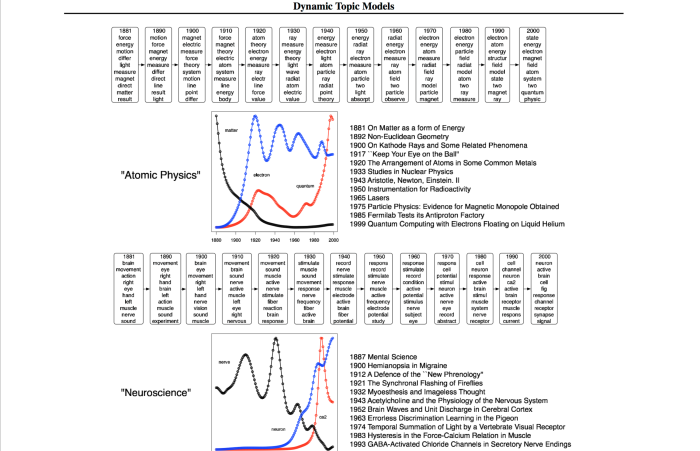
My posts on Topic Modeling do not mention any of the math behind this at all – I’ll try to address this by doing a blog post on the math behind this in a slightly hand-wavey manner, so you can at least intuitively figure out what is going on. In the mean time, the wiki does a decent job summarizing the evolution of parameters well.
Phew! Now that explaining what DTM does is done, I’ll be talking about my experience coding it up. Since there was already an implementation by Blei’s group, it made sense to tackle my problem by converting the C/C++ code to python. As a C++ newbie though, this was not at all easy.
The mere size of the code threw me off at first; I didn’t know where to start! Once I started getting at the main.c file and started converting, the thousands of methods and searching slowed me down tremendously. My mentor, Lev, advised me to get an IDE, so I chose to work with CLion, and it’s been a smooth experience so far.
With an IDE set up my task was considerably easier, but getting used to pointers (and sometimes pointers pointing to pointers to pointers!), and GSL (GNU Scientific Library) meant I was just crawling along. After a week or two of this though, my speed has considerably increased: I’m done converting and testing one of the major parts of the code. Of course, another major chunk of the code remains, but it does feel nice to start chipping away at it. You can follow my progress with my DTM Pull Request.
Working on DTM has taught me a lot, especially about code design and testing. Lev is a huge fan of testing based development, so I usually have unit tests ready after I finish up with each mathematical module. This way I can check every unit individually and know that stitching my results together will likely give me the right result. Another challenge is deciding when to re-use the gensim LDA code and when not to. It’s something I’m still experimenting with though, and hopefully I’ll have more clarity on this in my next blog post!
I hope you enjoyed reading about DTM, and my attempt at coding it for GSoC 2016. My midterm evaluation is going on this week, so these are busy times. I’ll still try to put out a few more posts about my experiences with Gensim, soon!
