 RARE Technologies
RARE TechnologiesLatent Dirichlet Allocation (LDA), one of the most used modules in gensim, has received a major performance revamp recently. Using all your machine cores at once now, chances are the new LdaMulticore class is limited by the speed you can feed it input data. Make sure your CPU fans are in working order!
The person behind this implementation is Honza Zikeš. Honza kindly agreed to write a few words about this new multicore implementation:
Why multicore?
The LDA module in gensim is very scalable, robust, well tested by its users and optimized in terms of performance, but it still runs only in single process, without full usage of all the cores of modern CPUs. Because in recent years CPUs with multiple cores has become standard even for low-end laptops, we decided a multicore implementation can be very useful and might save a lot of time waiting, especially for very large corpora.
In other words, my goal was to shorten LDA model training on English Wikipedia from overnight computation to over lunch computation 🙂
What could be parallelized in the LDA training?
Without going too much into the details (theory here), I can say that the “online variational Bayes” LDA training in gensim conceptually consists of Expectation-Maximization iterations, with alternating E-steps and M‐steps. In E‐step we perform inference on a chunk of documents. The sufficient statistics collected in E-step are accumulated and used to update the model in M-step. You can notice that in terms of improving the performance of the algorithm, one can quite easily distribute the E-step to several workers and by this possibly speed up the whole LDA model training.
How have I implemented the multicore LDA?
In order to distribute the E-step to all of the CPU cores, I have decided to use standard Python multiprocessing library, which is very easy to use (I’ve used it for the first time and it was pretty fast to learn it ;)). It offers plenty of useful features like process Pools or process safe Queues that were used for the multicore LDA implementation.
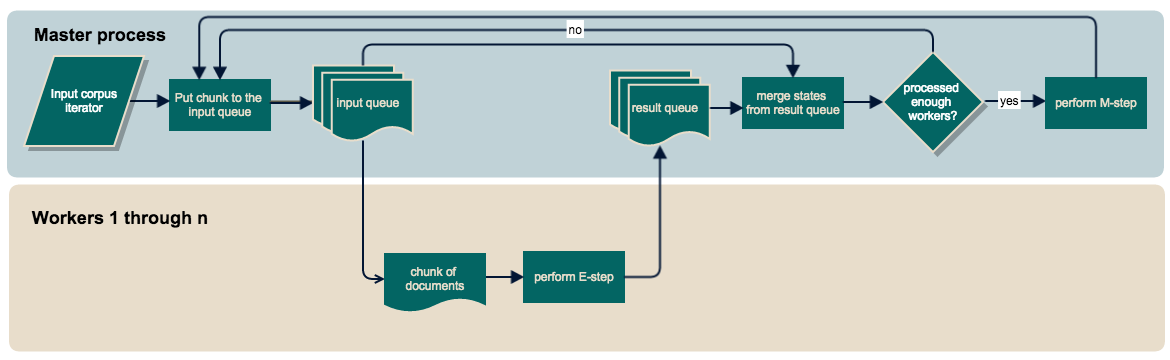
Now let’s say a little bit about the architecture of the newly implemented multicore LDA. I have decided to perform data reading, E-step result aggregation and M‐step in the master process. The master process streams through the input iterator, splits it into small in-memory chunks of documents, and puts each chunk into an input queue. Additional worker processes are created via the multiprocessing Pool and fed from this input queue. These workers perform E-steps and save updates to sufficient statistics to a result queue, from which the master reads them, aggregates them and updates the LDA model (M-step) every time we’ve aggregated “workers” number of chunks.
Conceptual flow of LDA multicore.
As you could notice this architecture implies that to get the best performance for your LDA model training, you should use “number of your machine’s physical cores – 1” workers, because obviously you need to reserve one core for the master process.
What about master process possibly blocking workers?
Yes, you can correctly see that I had to be very careful not to block workers by master process. This is the reason why I set a large enough input queue size, and call M-step in the master process only after having processed “workers” number of chunks. This assures that the only possibility of workers being blocked by the master process is when you would have enough workers (and of course also enough CPU cores :)) to perform all the E-steps faster than you are actually able to read the data from the input corpus iterator. If that happens, I’d recommend optimizing your input data reading mechanism 😉
Note from Radim: This actually happened to us in one client project. The input document stream was generated on-the-fly, including advanced tokenization and entity detection. The document stream throughput was low enough that it managed to sustain only two LDA workers, out of 7 workers available! The other five processes were just lazying around, waiting for input data to be generated by the master process, until we optimized the preprocessing better.
Did the multicore LDA actually speed up training?

To evaluate the time performance of newly implemented LDA multicore, I have decided to perform experiments on English Wikipedia in a same way as it is described at http://radimrehurek.com/gensim/wiki.html. Thus I have used following code to train the LDA model:>>> from gensim import corpora, models >>> >>> # load id-‐>word mapping (the dictionary) >>> id2word = corpora.Dictionary.load_from_text('./enwiki/wiki_wordids.txt') >>> >>> # load corpus iterator >>> mm = corpora.MmCorpus('./enwiki/wiki_bow.mm.bz2') >>> >>> # train LDA using 4 cores (1 master + 3 workers) >>> lda = models.LdaMulticore(mm, id2word=id2word, num_topics=100, workers=3)Thank to Radim who provided me this server (i7 with 4 real cores, 8 “fake” hyperthread cores), I was able to experiment with different numbers of workers. All experiments used online training, single pass over the entire Wikipedia corpus of 3.5 million documents, vocabulary size of 100,000 and asking for 100 LDA topics:
Wiki training times and accuracies for the various LDA implementations. algorithm training time final model perplexity real user sys 1 worker 2h30m 4h28m 34m 441.9 2 workers 1h25m 3h44m 25m 426.2 3 workers 1h6m 3h40m 23m 418.6 4 workers 1h4m 3h52m 23m 416.6 5 workers 1h2m 4h8m 22m 420.2 old LdaModel, for comparison 3h43m 3h25m 17m 443.9 just iterating over the input Wikipedia corpus, no LDA training = I/O overhead 20m22s 20m17s 2s N/A Apparently, i7’s eight hyperthread cores offer no real performance boost; the optimal number of workers still equals 3 = “number of real cores (4) minus one for the master process”. There’s no real improvement using more workers on this machine.
Radim’s technical note: to avoid having to synchronize workers at each M-step (which is a major bottleneck for throughput), we switched to a fully asynchronous E-M updates. This is a similar trick to the one used in word2vec (it even comes with some theory — see Jeff Dean &al’s Large Scale Distributed Deep Networks by Google).
Interestingly, and for reasons that are not at all obvious, this async aggregate-updates-and-synchronize-when-we-can approach actually improves accuracy, compared to the more “sharply defined”, synchronous E-M updates. In other words, letting the workers munch on possibly slightly out-of-date models in parallel is not only massively faster (no model synchronization point), but also leads to marginally more accurate models.
Practical stuff
-
Install/upgrade gensim to >=0.10.2.
-
Replace gensim.models.LdaModel with gensim.models.LdaMulticore in your code. Most parameters remain identical; see API for details.
-
Voila! Multiple times faster LDA training 🙂
If you liked this article, you may also like Optimizing deep learning with word2vec and Benchmarking nearest-neighbour (kNN) search libraries.

Comments 4
Hi,
I liked the “Conceptual flow of LDA multicore”. What tool did you used for this.
Regards
Suvir
Thank you so much for implementing multicore LDA! I already use distributed LDA on one computer to exploit multiple cores, and I wonder : is there a fundamental difference between using the distributed LDA and the multicore LDA?
good job
thankyou for notin this !! it was driving me nuts
Note from Radim: This actually happened to us in one client project. The input document stream was generated on-the-fly, including advanced tokenization and entity detection. The document stream throughput was low enough that it managed to sustain only two LDA workers, out of 7 workers available! The other five processes were just lazying around, waiting for input data to be generated by the master process, until we optimized the preprocessing better.