 RARE Technologies
RARE TechnologiesWe had recently published a large-scale machine learning benchmark using word2vec, comparing several popular hardware providers and ML frameworks in pragmatic aspects such as their cost, ease of use, stability, scalability and performance. Since that benchmark only looked at the CPUs, we also ran an analogous ML benchmark focused on GPUs.

Figure 1: Cost of training a bi-directional LSTM on twitter sentiment classification task (~1.5 million tweets, 4 epochs) across the various GPU hardware platforms.
Platforms
We include the following HW platforms in this benchmark: Amazon Web Services AWS EC2, Google Cloud Engine GCE, IBM Softlayer, Hetzner, Paperspace and LeaderGPU.
As many modern machine learning tasks exploit GPUs, understanding the cost and performance trade-offs of different GPU providers becomes crucial.
I'd like to thank all these providers for graciously providing us with benchmark credits and excellent support for the duration of my testing. I discuss and compare all platforms in much detail below, but each platform came with its own relative pros and cons and the GPUaaS market is a very exciting and lively space.
(As a side note, the only major provider who didn't communicate at all, in fact we had no response even from their official support channels, was Microsoft Azure. Draw your own conclusions.)
This HW provider list should be a good assortment of platforms with virtual instances (AWS, GCE), bare metal infrastructure (Softlayer), dedicated servers (Hetzner) and comparatively newer players specialized in providing GPUaaS (LeaderGPU, Paperspace). We look at two kinds of GPUs based on the prices of the instances on each platform – “budget” and “high-end” (see Table 1). The goal is to reveal whether the high-end instances get us their money’s worth.
Benchmark Setup
Task
Here at RARE Technologies we often deal with NLP problems, so I settled on a sentiment classification task for the benchmark. A bidirectional LSTM is trained to perform binary categorization of tweets. The choice of algorithm is otherwise not terribly important; my only true requirement for this benchmark is that it should be GPU intensive. To ensure maximum GPU utilisation, I made use of Keras’s (v2.1.3) fast LSTM implementation backed by CuDNN – the CuDNNLSM layer.
Dataset
We make use of the Twitter Sentiment Analysis Dataset containing 1,578,627 classified tweets, each row marked as 1 for positive sentiment and 0 for negative sentiment. The model is trained for 4 epochs on 90% of the (shuffled) data while the remaining held-out 10% is used for model evaluation.
Docker
For the purpose of reproducibility, I created an Nvidia Docker image which contains all the dependencies and data needed to re-run this benchmark. The Dockerfile and all the required code can be found in this Github repository.
We publish the setup and code in full, not only so anyone can reproduce these results, but also so that you can plug in your own HW platform or another algorithm of choice, to do your own benchmark.
Results
|
Type |
GPU |
GPU Memory |
Train Time (in hours) |
Final accuracy (on held out data) |
Instance |
Average GPU Utilisation |
Cost of one run (USD) |
|
|
Amazon’s AWS |
Low-end |
Tesla K80 |
12GB |
3.62 |
82.47% |
p2.xlarge |
78% |
$3.3 |
|
High-end |
Tesla V100 |
16GB |
1.06 |
82.23% |
p3.2xlarge |
67% |
$3.3 |
|
|
Google Compute Engine |
Low-end |
Tesla K80 |
12GB |
3.72 |
82.54% |
NVIDIA Tesla K80+ n1-standard-4 |
77% |
$2.4 |
|
High-end |
Tesla P100 |
16GB |
2.07 |
82.30% |
NVIDIA Tesla P100 +n1-standard-4 |
71% |
$3.4 |
|
|
Paperspace |
Low-end |
Quadro P6000 |
24GB |
1.82 |
82.24% |
P6000 |
76% |
$1.6 |
|
High-end |
Tesla V100 |
16GB |
1.09 |
82.59% |
V100 |
68% |
$2.5 |
|
|
Hetzner (dedicated server) |
|
GTX 1080 |
8GB |
2.27 |
82.46% |
ex51-ssd-gpu |
81% |
$0.5+ |
|
IBM's Softlayer |
Low-end* |
2 x Tesla M60 |
8GB |
3.16 |
82.22% |
bare metal instance |
85% |
$11.2 |
|
High-end* |
4 x Tesla K80 |
12GB |
4.1 |
82.57% |
bare metal instance |
62% |
$20.1 |
|
|
LeaderGPU |
Low-end* |
2 x GTX 1080 |
8GB |
2.12 |
82.29% |
- |
67% |
$3.13 |
|
High-end* |
2 x Tesla P100 |
16GB |
2.42 |
82.26% |
- |
42% |
$14.26 |
|
|
Low-end** |
2 x GTX 1080 |
8GB |
2.49 |
82.50% |
- |
71% |
$3.7 |
|
|
High-end** |
2 x Tesla P100 |
16GB |
1.86 |
82.32% |
- |
74% |
$11.0 |
Table 1: Summary of the benchmark results.
*These are multiple GPU instances in which models were trained on all GPUs using Keras’s multi_gpu_model function that was later found out to be sub-optimal in exploiting multiple GPUs.
**These are multiple GPU instances in which models were trained using only one of their GPUs due to the above reasons.
+Hetzner provides dedicated servers on a monthly basis. Figures here reflect hourly prorated costs.
Evaluation: Ease of Ordering, Setup and Use
I have commented on my experience with using AWS, Softlayer and GCE in my prior post. Ordering an instance on LeaderGPU and Paperspace is plain sailing without any complicated settings. The provisioning time for Paperspace and LeaderGPU was a tad longer (couple of minutes) when compared to AWS or GCE which were up within a few seconds.
LeaderGPU, Amazon and Paperspace offer freely available Deep Learning Machine Images which come pre-installed with Nvidia drivers along with the Python development environment, and the Nvidia-Docker – essentially the whole nine yards required to start the experiments right off the bat. While this makes life significantly easier, especially for beginners who just wish to experiment with Machine Learning models, I set up everything from scratch (except for LeaderGPU) the old school way, in order to evaluate the ease of customizing an instance to individual needs. In this process, I faced a few issues common with all the platforms, such as NVIDIA driver incompatibility with the installed gcc version, or the GPU usage reaching 100% after installing the driver without any evidence of a running process. Unexpectedly, running my Docker on a Paperspace low-end instance (P6000) resulted in an error. This problem was caused by the Tensorflow on Docker being built from source with CPU optimizations (MSSE, MAVX, MFMA) which the Paperspace instance did not support. Running a Docker without these optimisations fixed the snag.
With regards to stability, I faced no issues whatsoever with any of the platforms.
Cost
Unsurprisingly, dedicated servers are the best bet to keep costs under control. This is because Hetzner charges on a monthly basis which translates to exceedingly low hourly prices and the figure depicts prorated costs. Of course, this only holds true as long as you have enough tasks to keep the server sufficiently busy. Amongst the virtual instance providers, Paperspace is the clear winner. It is twice as cheap to train a model on Paperspace than on AWS in the lower end GPUs segment. Paperspace further shows similar cost-effectiveness in the high-end GPUs division.
Here's Table 1 summarized into a graph again:
Figure 1: Cost of training a bi-directional LSTM on twitter sentiment classification task (~1.5 million tweets, 4 epochs) across the various GPU hardware platforms.
Between AWS and GCE, there seems to be a trend reversal when going from low end to high-end GPUs. GCE is significantly cheaper than AWS in the lower end GPUs segment while it is slightly costlier than AWS when we look at pricey GPU instances. This suggests the expensive AWS GPUs might to be worth their extra cost providing the bang for the buck they are expected to yield.
IBM Softlayer and LeaderGPU appear expensive, mainly due to under-utilisation of their multi-GPU instances. The benchmark was carried out using the Keras framework whose multi-GPU implementation was surprisingly inefficient, at times performing worse than a single GPU run on the same machine. But neither of these platforms offers a single GPU instance. The benchmark run on Softlayer utilized all available GPUs using Keras’s multi_gpu_model function while the one on LeaderGPU only utilized one out of the available GPUs. This led to considerable extra costs for the under-utilized resources. Also, LeaderGPU provides more powerful GPUs, GTX 1080 Ti & Tesla V100, at the same prices (per minute) as GTX 1080 and Tesla P100 respectively. Running on these servers would have definitely gotten the overall costs down. Taking all this into account, LeaderGPU’s low-end costs seen in the plot seem to be actually quite reasonable. Bear that in mind, especially if you're planning to use a non-Keras framework that makes better use of multiple GPUs.
There also appears to be another general trend – cheaper GPUs give better performance/price ratio than the pricier GPUs, indicating that the decrease in training time does not offset the increase in total cost.
A side note on training training multi-GPU models using Keras
A large number of people in academia and industry are immensely comfortable with using high-level APIs like Keras for Deep Learning models. Since its one of the most accepted and actively developed deep learning frameworks, users would expect a speedup on switching to multi-GPU model without any additional handling. But this is certainly not the case, as evident from the plot below. The speedup is rather unpredictable – there is clearly a speedup on the “dual GTX 1080” server while the multi-GPU training took even longer to finish compared to the single-GPU training on the “dual P100” server. This sentiment also revealed itself in a few other blogs and issues on Github that I came across while investigating what’s going on with the costs.
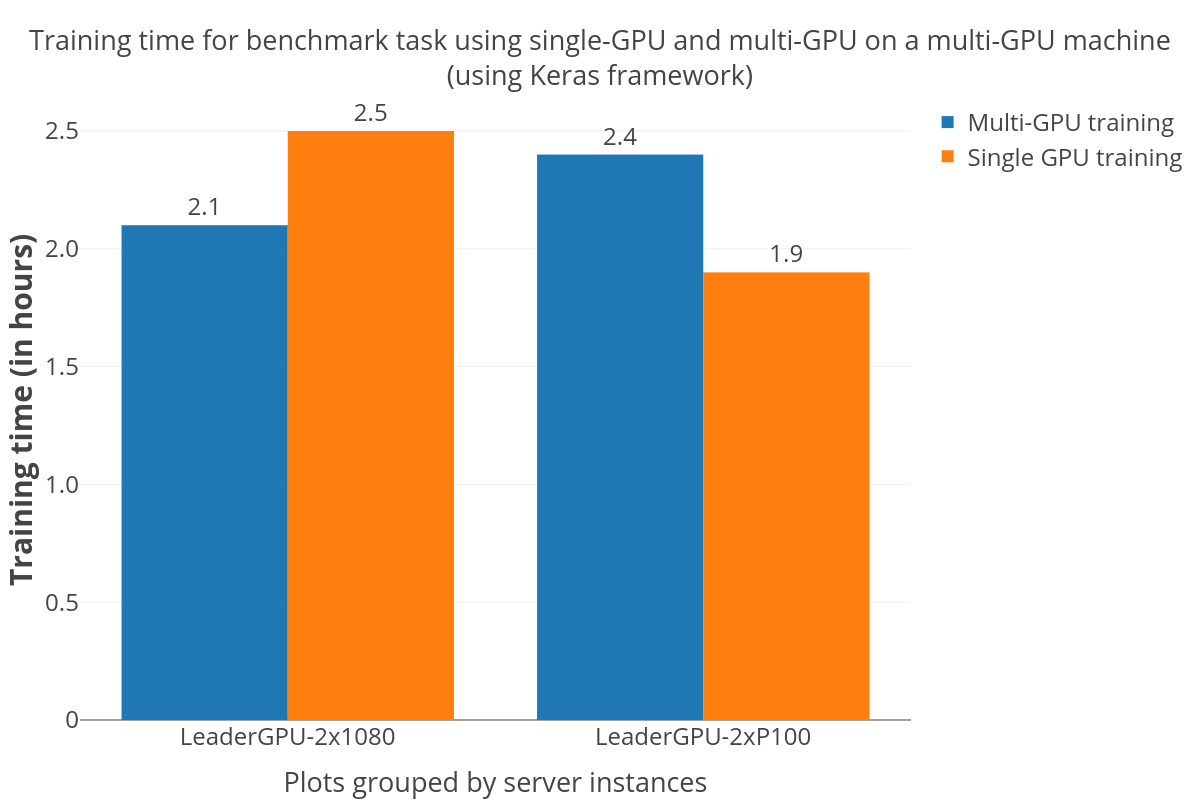
Figure 2: Training times taken by multi-GPU and single-GPU training (on otherwise identical machines) using Keras.
Model Accuracy
For sanity testing, we inspected the final model accuracies at the end of training. As evident from Table 1, there were no notable differences which reaffirms that the underlying hardware/platform has no impact on the quality of training, and that the benchmark was correctly set up.
HW Pricing
GPU prices change frequently, but at the moment, AWS provides K80 GPUs (p2 instances) starting at $0.9/hr which are billed in one second increments whereas the more powerful and performant Tesla V100 GPUs (p3 instances) commence at $3.06/hr. Additional services like data transfer, Elastic IP addresses, and EBS Optimized Instances come at extra costs. GCE is an economical alternative which provides Tesla K80 and P100 on-demand starting at $0.45/hr and $1.46/hr respectively. These are billed in one second increments and offer appreciable incentives via their usage based discounts. Although, unlike AWS they need to be attached to a CPU instance (n1-standard-1 at $0.0475/hr).
Paperspace rivals GCE in the low cost league with rates for dedicated GPUs starting from Quadro M4000 at $0.4/hr to Tesla V100 at $2.3/hr. Apart from the customary hourly fees, they also levy a flat monthly charge ($5/month) which covers storage and maintenance. Paperspace bills on millisecond basis, add-on services can be availed at supplemental costs. Hetzner only offers one dedicated server with GTX 1080 on a monthly basis with an additional one time setup charge.
IBM Softlayer is one of the very few platforms on the market which provides bare metal servers with GPUs on monthly and hourly basis. It offers 3 GPU servers (containing Tesla M60s & K80s) starting from $2.8/hr. These servers have a static configuration, meaning their customization possibilities are limited compared to the other cloud providers. Softlayer’s billing in hourly increments is cruder too, and can turn out to be costlier for short-running tasks.
LeaderGPU, a relatively newer player, provides dedicated servers with a diverse range of GPUs (P100s, V100s, GTX 1080s, GTX 1080Ti). Users can avail monthly, hourly or per minute pricing which are billed per second. Servers have a minimum of 2 GPUs up to 8 GPUs, with prices from 0.02€/min to 0.08€/min.
Spot/Preemptive Instances
Some of the platforms provide significant discounts (50%-90%) on their spare compute capacity (AWS spot instances and GCE’s preemptive instances) although they can terminate (and restart) unexpectedly. This leads to highly unpredictable training times since there is no guarantee when the instance would be up again. That is fine for applications that can handle such terminations but many tasks, for instance, time-bound projects wouldn’t fare well in this case, especially if you consider the wasted labor hours. Running tasks on preemptive/spot instances requires additional code to handle the termination and re-start of instances gracefully (checkpointing/storing data to a persistent disk etc.).
Also, the spot price fluctuations (in case of AWS) can cause the costs to depend heavily on the supply-demand of capacity at the time of the benchmark run. We'd need multiple runs to average out the costs.
In short, while you can save money with spot/preemptive instances if you're careful, I did not include them in this benchmark because of these complications.
Closing comments
- Paperspace appears to be one step ahead with regards to performance and costs. This is especially true for occasional/infrequent users who just wish to experiment with deep learning techniques (similar conclusion in another benchmark).
- Dedicated servers (like the ones provided by LeaderGPU) and bare metal servers (such as Hetzner) are suitable for users considering heavy-duty long term employment of these resources (doh). Note though that since they are less flexible in the matter of customizing the servers, make sure that your task is highly CPU/GPU intensive to truly benefit from the pricing.
- Newer players like Paperspace and LeaderGPU shouldn’t be dismissed, as they can aid in cutting a major chunk of the costs. Enterprises can be averse to switching providers because of the associated inertia and switching costs, but these smaller platforms are definitely worth considering.
- AWS and GCE can be terrific options for someone looking for integration with their other services (AI integrations – Amazon’s Rekognition, Google’s Cloud AI).
- Unless you plan to run a task that will take days to complete, sticking to a lower end single-GPU instance is the best bargain (see also here).
- Higher-end GPUs are significantly faster but actually have worse ROI. You should opt for these only when a short training time (lower R&D cycle latency) is more important than the hardware costs.
We gratefully acknowledge support by AI Grant which made these (sometimes costly) experiments possible.
