 RARE Technologies
RARE TechnologiesThe rise of machine learning as a discipline brings new demands for number crunching and computing power. With easily accessible and cheap hardware resources, one has to pick the right platform to run the experiments and model training on.
Should you use Amazon’s AWS EC2 instances? Or go with IBM’s Softlayer, Google’s Compute Engine, Microsoft’s Azure? How about a real dedicated server, such as the ones offered by Hetzner?
With no clear benchmark to address the practical aspects of choosing a hardware and software platform for ML, individuals and small companies like to go ahead with the popular choice. This is often suboptimal.
This is part one in a blog post series by our Incubator student Shiva Manne compares machine learning frameworks and hardware platforms from practical aspects, such as their ease of use, cost, stability, scalability and performance. We gratefully acknowledge support by AI Grant and IBM Global Entrepreneurship program, which made these (sometimes costly) experiments possible.
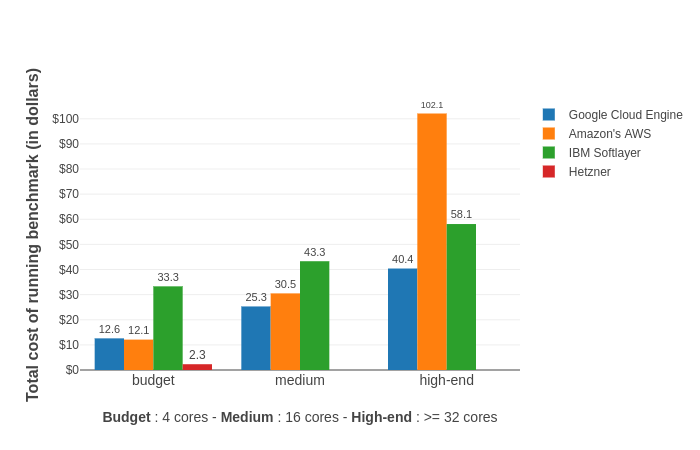
Figure 1: The cost of training a model on different hardware providers. The same benchmark task is run from a Docker container on 3 kinds of instances on each platform, which we call budget, medium and high-end, with the total cost in US dollars recorded.
Benchmark setup
Hardware platforms: the contestants
Relevant metrics are collected from benchmark runs on Hetzner’s dedicated servers, Amazon’s AWS, Google’s Compute Engine and IBM’s Softlayer. These platforms were chosen on the basis of their popularity. We consider 3 kinds of machine instances — budget, medium & high-end (see table 1). This categorisation of machines is based on their cost ($/hr) which, for this CPU intensive benchmark, is primarily dependent on the total number of CPU cores it contains.
For benchmarking Spark MLlib, we run the model on Google’s Cloud Dataproc. It is a fast, easy-to-use and fully managed cloud service for running Apache Spark and Apache Hadoop clusters.
The benchmark task: why Word2Vec?
The choice of a benchmarking algorithm is hard, bound to create controversy and nitpicking no matter what. We decided to go with Word2Vec, because it combines several pleasant properties:
- It is a practical algorithm, with countless exciting applications and a wide range of usage in both industry and academia. No more “counting words”.
- Word2vec is a computation-heavy algorithm: most time is spent in number crunching, leading to a hardcore high performance computing profile. This is great for benchmarking.
- Word2vec is also easy to parallelize, which means we can test the scaling properties of both hardware and software.
- Word2vec has a stellar reference implementation by the original authors (you cannot really diss something signed off by Jeff Dean!). This makes sanity and accuracy checking much easier – there’s no argument about what it should do.
- It’s been around for more than 4 years and has become a cornerstone in ML practice. Machine learning frameworks have no excuse for not shipping a sane implementation for training word embeddings like Word2Vec.
In short, we use Word2Vec as a gentle proxy for measuring the quality of ML frameworks, to gain insights about their performance, robustness and scalability. At the same time, we also use it to compare the bang-for-buck ROI of different hardware providers.
Evaluation of the cloud platforms
|
HW
(hours / GB RAM) SW |
Google Compute Engine |
Amazon Web Services |
IBM’s Softlayer |
Hetzner |
||||||
|
Budget 4 cores |
Medium 16 cores |
HighEnd 32 cores |
Budget 4 cores |
Medium 16 cores |
HighEnd 36 cores |
Budget 4 cores |
Medium 16 cores |
HighEnd 40 cores |
||
|
Original-C (cloned repo in Aug 2017) |
3.8 / 1.0 |
1.0 / 1.0 |
0.5 / 1.1 |
3.9 / 1.0 |
0.8 / 1.0 |
0.6 / 1.1 |
4.0 / 1.0 |
1.2 / 1.0 |
0.6 / 1.1 |
1.5 / 1.0 |
|
Gensim |
4.6 / 1.1 |
1.7 / 1.2 |
1.4 / 1.2 |
4.8 / 1.1 |
1.5 / 1.2 |
1.7 / 1.2 |
4.5 / 1.1 |
1.8 / 1.1 |
1.6 / 1.2 |
2.0 / 1.1 |
|
DL4J |
13.9 / 7.2 |
5.7 / 7.0 |
4.8 / 10.2 |
16.9 / 4.7 |
5.0 / 6.8 |
9.0 / 12.2 |
15.9 / 7.7 |
10.6 / 6.7 |
10.0 / 18.4 |
5.4 / 11.2 |
|
Tensorflow(v 1.3.0) |
36.2 / 14.2 |
35.3 / 14.2 |
38.1 / 15.9 |
34.7 / 14.1 |
30.9 / 14.2 |
52.9 / 14.2 |
30.1 / 14.2 |
42.0 / 14.2 |
29.9 / 14.2 |
14.4 / 14.2 |
Table 1 (scroll right to see more platforms): Summary of the benchmark results. Each cell indicates the training time (in hours) and peak memory (in GB). Long table — scroll to the right to see other platforms. More on the software frameworks, including results for the latest DL4J version, in the next post.
A note on repeatability
Repeatability is clearly critical for any benchmark and we like to keep things above board. For this reason, we’re releasing all datasets, code and details, so you can review, repeat or even extend these experiments:
- Dataset: The word vectors are trained on the English Wikipedia corpus dump dated 01-05-2017 (14GB of xml.bz2; download here). This raw dump format is pre-processed using this code to yield a plain text file containing one article per line, with punctuation removed and all words converted to lowercase. The first 2 millions lines of this pre-processed wiki corpus (download here; 2GB of gzipped plain text, 8GB unzipped) are used to train the Word2Vec on each framework and platform.
- Docker: The benchmarks are run inside a Docker container to ensure a standardized environment while training the models. To profit from SSE/AVX/FMA optimizations, this Docker container is built by compiling Tensorflow from source. Each benchmark instance is trained for 4 epochs using the skipgram model with negative sampling and the exact same parameter values. I have created a dedicated repository for this benchmarking project, containing all the resources required to run/repeat the benchmark.
Ease of setup & use, stability
We found IBM’s Softlayer to be highly “new-user” friendly, which greatly expedited the process of configuring and ordering an instance. The experience was similar while ordering a dedicated server from Hetzner’s portal.
This wasn’t as easy with Google’s product – with GCE, I had to spend around 15 minutes pondering over the numerous mandatory fields (like private keys, firewall rules, subnets etc.). An unsatisfactory customer support experience only compounds their problems.
AWS fits somewhere in between the two cloud platforms in terms of ease of setting up an instance.
With regards to stability, I had no issues with either AWS, Softlayer or Hetzner. However, when running a long task (the benchmark with Tensorflow-GPU) on GCE, the job abruptly stopped after a few days without showing any errors, and I couldn’t figure out why. A repeated attempt also resulted in the same failure.
Another difference between these platforms is the time required to provision an instance after placing an order. Softlayer lacks in this regard with provisioning sometimes taking up to 20 minutes. AWS and GCE takes at most a couple of minutes. Like most dedicated server providers, Hetzner takes anywhere from an hour to a day to set up and get the machine up and running.
Hardware cost
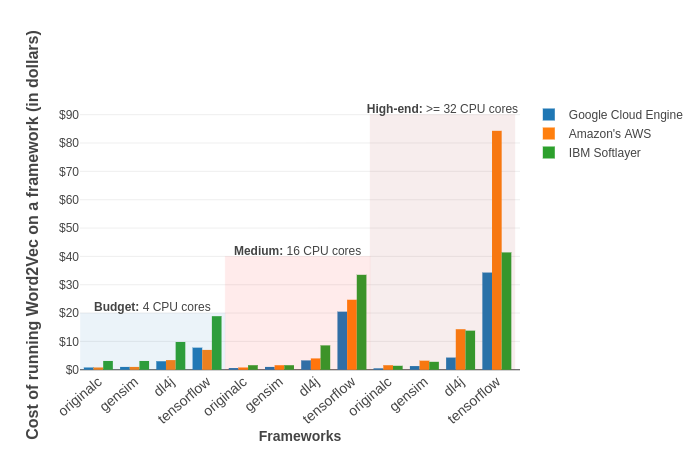
Figure 2: Cost of training different Word2Vec implementations across the cloud platforms with different kinds of instances (budget, medium, high-end).
Dedicated servers come out on top when comparing prorated costs (even though these are charged on a monthly basis and have no hourly option) against virtual machines by a huge margin. Of all the virtual instances providing cloud platforms, GCE is undeniably one of the more inexpensive ones. Compared to Amazon’s complex pricing, GCE’s pricing is lucid and straightforward with no hidden costs. They also keep expenses in check better than others by offering features such as no upfront costs, per-second billing and automatic sustained use discounts.
Amazon has a fairly low approval rating concerning its pricing/billing, a sentiment evinced in a large number of benchmarks and blogs. Although looking at figure 1, this doesn’t seem to be entirely accurate since AWS comes across as reasonably cheap in the budget-medium range. As it happens, it unexpectedly surpasses even GCE in the budget instances. Juxtaposing the high-end instances uncloaks the huge differences in the costs between AWS and other platforms in this segment. The price gap between Softlayer and AWS is not enormous but the costs for AWS eclipses all the other platforms completely, telling us that the high prices charged by AWS for premium instances are not backed by expected performance speedups, at least for these kind of intense number-crunching tasks.
Softlayer outperforms AWS in this regard, where its higher end (pricier) instances correspond to performance improvements as expected. Softlayer is also the only platform that allows the provisioning of bare metal servers amongst the 3 cloud service providers, which might be useful under security or compliance constraints.
Softlayer & GCE allow you to custom configure instances, which aids in keeping the costs low while AWS customers are required to choose from a predefined set of instances and then over-provision resources (CPUs & RAM) according to their needs. Another winning/distinguishing point for GCE is the granularity of time that it uses to bill customers, in per-second increments. Starting this October, AWS has also adopted per-second billing while Softlayer continues to charge on an hourly basis. Additionally, we had a serious issue with Softlayer where the price would not update properly for weeks, showing an outdated monthly cost that caused us to overshoot our monthly budget. Very unpleasant, not good.
It becomes apparent from the above plot that barring original C, all the other software frameworks cost more to train on hardware instances with better configs and that the expected decrease in training time (owing to more CPU cores) does not justify the price of these extra resources. A similar conclusion can be drawn by plotting the cost of training a Word2Vec model using Spark MLlib with different cluster sizes:
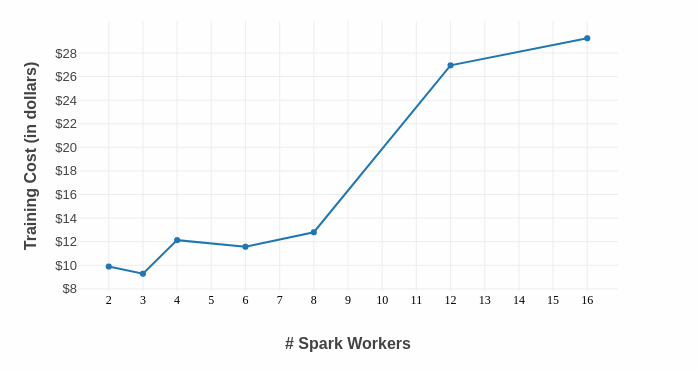
Figure 3: The MLlib implementation of Word2Vec in Spark doesn’t scale very well; the optimal ROI point comes at mere 3 workers.
TL;DR Summary
|
Cloud Platform |
Strengths |
Weaknesses |
|
Google Compute Engine |
|
|
|
Amazon Web Services |
|
|
|
IBM Softlayer |
|
|
|
Hetzner |
|
|
A few more general observations:
- The performance of most frameworks does not scale well with additional CPU cores beyond a certain point (8 cores), even on machines with many more cores.
- Fewer cores with high clock speeds perform much better than high number of cores with low clock speeds. Stick to the former to cut overall costs.
- Dedicated servers like Hetzner can be an order of magnitude cheaper than cloud, for the high performance and free bandwidth they provide. You should definitely take this into consideration while renting machines for extended (month+) periods of use.
In some of the images above, you could already see we were running a battery of tests not only against the hardware providers, but also against different software platforms. How do the machine learning frameworks compare?
In the next post of this series, we’ll dig deeper and investigate the ease of use, documentation and support, scalability and performance of several popular ML frameworks such as Tensorflow, DL4J or Spark MLlib. Stay tuned or subscribe to our newsletter below. EDIT: the next part benchmarking GPU platforms is here!
Appendix
|
HW Provider- Instance |
Model |
virtual CPU cores |
RAM |
|
AWS-Budget |
Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz |
4 |
16GB |
|
AWS-Medium |
Intel(R) Xeon(R) CPU E5-2666 v3 @ 2.90GHz |
16 |
30GB |
|
AWS-High End |
Intel(R) Xeon(R) CPU E5-2666 v3 @ 2.90GHz |
36 |
60GB |
|
GCE-Budget |
Intel(R) Xeon(R) CPU @ 2.20GHz |
4 |
26GB |
|
GCE-Medium |
Intel(R) Xeon(R) CPU @ 2.20GHz |
16 |
32GB |
|
GCE-High End |
Intel(R) Xeon(R) CPU @ 2.30GHz |
32 |
48GB |
|
Softlayer-Budget |
Intel(R) Xeon(R) CPU E5-2683 v4 @ 2.10GHz |
4 |
32GB |
|
Softlayer-Medium |
Intel(R) Xeon(R) CPU E5-2683 v4 @ 2.10GHz |
16 |
32GB |
|
Softlayer-High End |
Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz |
40 |
130GB |
|
Hetzner |
Intel(R) Quad Core(TM) i7-7700 CPU @ 3.60GHz |
8 |
64GB |
