RARE Technologies
RARE Technologies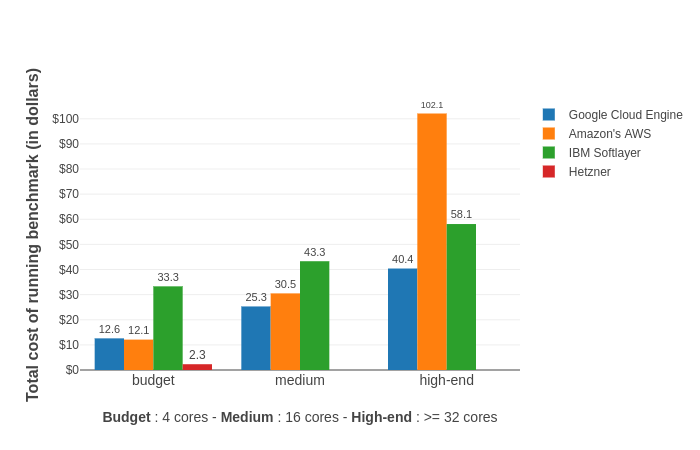
Machine learning benchmarks: Hardware providers (part 1)
The rise of machine learning as a discipline brings new demands for number crunching and computing power. With easily accessible and cheap hardware resources, one has to pick the right platform to run the experiments and model training on. Should you use Amazon’s AWS EC2 instances? Or go with IBM’s Softlayer, Google’s Compute Engine, Microsoft’s Azure? How about a real …