 RARE Technologies
RARE TechnologiesThis is a blog post by one of our Incubator students, Ji Xiaohong. Ji worked on the problem of aligning differently trained word embeddings (such as word2vec), which is useful in applications such as machine translation or tracking language evolution within the same language.
I was working on the Translation Matrix project, an idea originally proposed by Mikolov et al in 2013 [2], from Gensim’s wiki page of Project Ideas. The project is designed to exploit similarities among languages for machine translation. The technique can automate the process of generating dictionaries and phrase tables [2]. A translation matrix is trained to learn a linear projection between vector spaces that represent different languages (or just different embedding spaces in general). The representation of languages can be using either the distributed skip-gram or continuous bag-of-words model [3].
The Translation Matrix works by assuming the entity of each two languages share similarities in the geometric arrangement in both space (i.e. the relative position is similar in their spaces). We can visualize it in two dimensional coordinates. From Figure 1 we can visualize the vectors (all the vectors were projected down to two dimensions using PCA) for numbers in English and Italian. You can easily see that those word have similar geometric arrangement in both space.
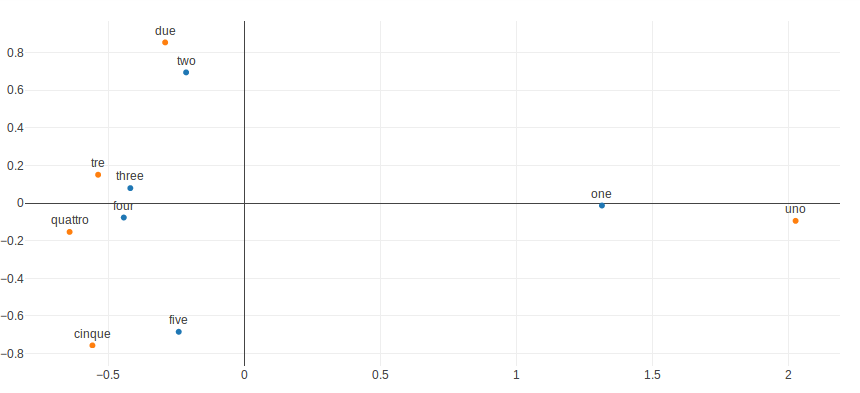
Figure 1. The relative position of each word.
With this assumption, the main algorithm learns a linear mapping from the source language representation to the target language representation. During translation, it project the input word to be translated into the target space, and returns words with a representation closest in the target space.
Here is an example of the usage of Translation Matrix. We’ll be training our model using the English -> Italian word pairs from the OPUS collection (which can be download from this link). This corpus contains 5000 word pairs.
from gensim.models import translation_matrix
from gensim.models import KeyedVectors
train_file = 'OPUS_en_it_europarl_train_5K.txt'
with utils.smart_open(train_file, 'r') as f:
word_pair = [tuple(utils.to_unicode(line).strip().split()) for line in f]
# Load the source language word vector
# The pre-trained model can be download form this link(https://pan.baidu.com/s/1nv3bYel).
source_word_vec_file = 'EN.200K.cbow1_wind5_hs0_neg10_size300_smpl1e-05.txt'
source_word_vec = KeyedVectors.load_word2vec_format(source_word_vec_file, binary=False)
# Load the target language word vector
# The pre-trained model can be download form this link(https://pan.baidu.com/s/1boP0P7D).
target_word_vec_file = 'IT.200K.cbow1_wind5_hs0_neg10_size300_smpl1e-05.txt'
target_word_vec = KeyedVectors.load_word2vec_format(target_word_vec_file, binary=False)
# create translation matrix object
transmat = translation_matrix.TranslationMatrix(word_pair, source_word_vec, target_word_vec)
transmat.train(word_pair)
print 'the shape of translation matrix is:', transmat.translation_matrix.shape
# translation the word
words = [('one', 'uno'), ('two', 'due'), ('three', 'tre'), ('four', 'quattro'), ('five', 'cinque')]
source_word, target_word = zip(*words)
translated_word = transmat.translate(source_word, 5)
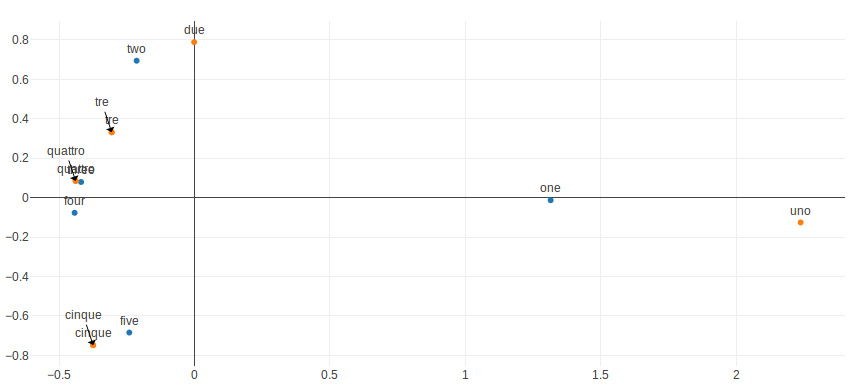
Figure 2. You see two kind of color nodes, one for English and the other for Italian. For the translation of word `five`, we return the top-3 most similar words: `[u’cinque’, u’quattro’, u’tre’]`. We can see that in this case, the translation is quite convincing. See [2] for the research paper by Mikolov et al.
All the Python commits I have done can be found in this pull request. There’s a lot of discussion about the project in that PR. For a tutorial on the use of this new functionality, please refer to my translation_matrix.ipynb notebook (now merged into gensim).
Finally, I would like to thank RaRe Technologies for giving me the opportunity to participate in this incubator program and providing the experimental environment and hardware. And I do also really thank my mentor Menshikh Ivan, Lev Konstantinovskiy, Gordon Mohr and other community members for providing the kind guidance and support throughout the project. I learned a lot about design patterns, unit test, git and time management this summer!
References:
- [1]: Dinu G, Lazaridou A, Baroni M. Improving zero-shot learning by mitigating the hubness problem. Computer Science, 2015, 9284:135-151.
- [2]: Mikolov T, Le Q V, Sutskever I. Exploiting Similarities among Languages for Machine Translation. Computer Science, 2013.
- [3]: Mikolov, Tomas, et al. “Distributed representations of words and phrases and their compositionality.” Advances in neural information processing systems. 2013.
- [4]: http://clic.cimec.unitn.it/%7Egeorgiana.dinu/down/
