 RARE Technologies
RARE TechnologiesSorry for not posting in such a long while. It had been a turbulent few weeks with some sharp twists and turns involving mails flying back and forth and a few pivots here and there. To validate the topic coherence pipeline in gensim, my plan was to work with the RTL-Wiki corpus and reproduce the results stated in the paper. You can read the exciting sequence of events in my live blog here. In this blog post I will talk about how I finally managed to verify the coherence pipeline in gensim after struggling for quite some time figuring out exactly how I’m going to do the benchmark testing.
Automating manual topic annotators using the right coherence measure
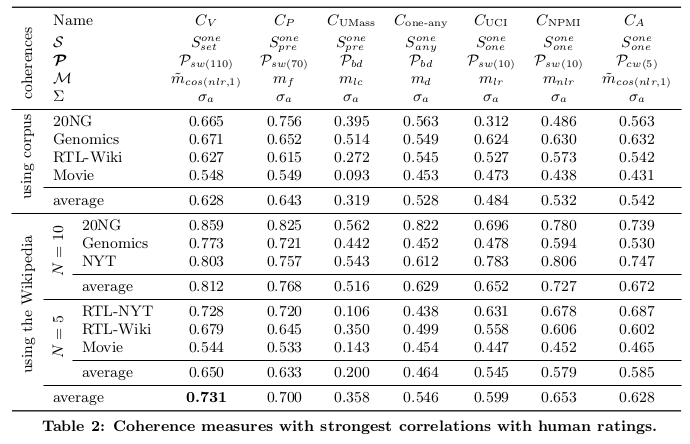
The whole purpose of the topic coherence pipeline is to automatize the manual topic annotators. However this can be a tricky business. Different coherence measures can give different correlations with the human ratings. The solution to this problem is to do a grid search kind of a thing wherein all the different pipeline parameters have to be tried out over a number of different datasets and then aggregated to see which coherence measure performs the best. c_v gives the best results however it’s much slower than u_mass. A tradeoff between the two can be achieved by using the c_uci or c_npmi coherence measure. Both of these have also now been added to gensim as part of this PR.
Importance of benchmark testing
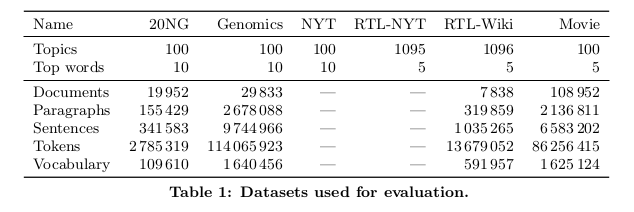
Any code which is adapted from a paper or an existing applet has to be benchmarked against trusted numbers to confirm whether it is working as expected or not. Gensim had released the alpha of the topic coherence pipeline almost a month back but the final stretch (and probably the most important one) involving benchmark testing was still left. The paper had the results of benchmark testing on several datasets. My job was to choose one, perform benchmark testing and finally compare the values with the ones in the paper. If they match; wonderful! If they don’t, well something somewhere doesn’t add up. Here are the datasets used in the paper.
The benchmark testing in this case followed this pipeline:
1. Choose a dataset.
2. Choose a set of topics on which the coherence measure has to be calculated.
3. Download the human ratings on the interpretability of these topics which is already available.
4. Calculate correlation of the coherence measure values (pearson’s r in this case) with the human ratings.
5. See if these correlation results match with those in the paper.
You can find some of those datasets and all of the topics along with their human ratings here. These were the correlation results from the paper:
Here is how it all panned out
RTL-Wiki
The raw RTL-Wiki was an html dump which had to be parsed and then created into a corpus. This parsing script would have to be prepared and I thought this would take some significant amount of time. I had also mailed Mr Roeder asking if he had any such script already prepared. He didn’t have any such script but he did have a java lucene corpus. I then read a bit about pylucene and thought about integrating a wrapper into gensim but that would branch off from the actual project for a week or two. Using a lucene thus seemed troublesome so I pivoted to the 20NG corpus.
20NG
The 20NG corpus is readily available in scikit learn and can be used through the sklearn API. However when I actually wrote the script to perform the benchmark testing, the values I got for the number of documents and the vocabulary size was very different from that mentioned in the paper. The number of documents was off by about 900 and the vocabulary was off by a huge number. I still ran the whole script and the c_v correlation came out to be pretty close to the expected value but u_mass was quite off. I can’t really blame the coherence pipeline for this since the number of documents was so off. I needed something better for benchmark testing. I saw that the movies corpus was pretty easy to preprocess and was easily downloadable from the above link. So I decided to pivot (again) to the movies corpus. You can find the ipython notebook for benchmark testing on 20NG here.
Movies
I downloaded the movies corpus from that link and got going. The numbers were still off but this time I was getting more documents than expected. I emailed Mr Roeder regarding how he had preprocessed the corpus. The preprocessing done in this paper has been described well here. I have to admit, my preprocessing was elementary at best but I still decided to go ahead with it. By the way, as Lev says, preprocessing is 80% of NLP work and it’s absolutely true! I was encouraged by the fact that the u_mass correlation result was very close to the expected one. However because c_v uses a sliding window for probability estimation and uses the indirect confirmation measure, it takes almost 13 times longer to run on the full dataset. I was ready to wait for 20 hours to see if c_v also gave a correct value but before running this I decided to tweak the sliding window algorithm a bit. The original sliding window moves over the document one word token per step, i.e. if the document is [a, b, c, d] and the window size is 2, the “virtual” documents will be defined as such:
Doc 1: {a, b}
Doc 2: {b, c}
Doc 3: {c, d}
I tweaked the algorithm to run by skipping the the already encountered tokens by defining the virtual documents as:
Doc 1: {a, b}
Doc 2: {c, d}
I did this to get an approximate result of c_v on the movies dataset. While using the original sliding window, the coherence measure took 12 minutes to evaluate one topic whereas with the new algorithm c_v ran on the full dataset in just 26 minutes. It also gave a value which was very much in accordance with what was expected so I decided to invest the 20 hours. In the meanwhile I had also improved the backtracking algorithm for calculating the context vectors in the indirect confirmation measure. I have already posted a PR for this. So I started the script and kept it overnight. It carried on through the next day and I made a live blog post when 2 hours were left for completion. As time passed, my nervousness grew exponentially. When the pipeline was processing the last set of topics, I closed my eyes and hoped for the best. Finally when it was done with all the topics at 9:40 pm IST, I was very hesitant to run the last cell which calculates the pearson correlation coefficient for u_mass and c_v. But I had to. So I did and I had my Eureka moment right there! c_v with the old algorithm gave a correlation which was much closer to what was expected! That wrapped it up. You can find the notebook here.
With this the final checkpoint was passed and the initial topic coherence pipeline of gensim, validated.
Future Work
The speed of u_mass and c_v can be vastly improved by cythonising some of the operations or using an indexing strategy for sliding window in the indirect_confirmation module. I will surely work on that as it’ll be a great opportunity to learn cython. Also, there is room for adding a number of other confirmation measures along with the different algorithms for the various pipeline stages. This will give the users a much broader range of measures to choose from. I expect to encounter some bug reports as well whenever this is done.
Finally I’d like to thank Lev and Radim for the assistance offered during this project. This wouldn’t have been possible without your help! Also, a huge shout out to Michael Roeder of the AKSW team for helping me out at every stage and also dealing with so many emails of mine! As I have said in the past too, it has been an absolute pleasure working on gensim with RaRe Technologies as part of the incubator programme!
