 RARE Technologies
RARE TechnologiesWhat exactly is this topic coherence pipeline thing? Why is it even important? Moreover, what is the advantage of having this pipeline at all? In this post I will look to answer those questions in an as non-technical language as possible. This is meant for the general reader as much as a technical one so I will try to engage your imaginations more and your maths skills less.
Imagine that you get water from a lot of places. The way you test this water is by providing it to a lot of people and then taking their reviews. If most of the reviews are bad, you say the water is bad and vice-versa. So basically all your evaluations are based on reviews with ratings as bad or good. If someone asks you exactly how good (or bad) the water is, you blend in your personal opinion. But this doesn’t assign a particular number to the quality of water and thus is only a qualitative analysis. Hence it can’t be used to compare two different sources of water in a definitive manner.
Since you are a lazy person and strive to assign a quantity to the quality, you install four different pipes at the end of the water source and design a meter which tells you the exact quality of water by assigning a number to it. While doing this you receive help from a lot of wonderful people around you and therefore you are successful in installing it. Hence now you don’t need to go and gather hundred different people to get their opinion on the quality of water. You can get it straight from the meter and this value is always in accordance with the human opinions.
The water here is the topics from some topic modelling algorithm. Earlier, the topics coming out from these topic modelling algorithms used to be tested on their human interpretability by presenting them to humans and taking their input on them. This was not quantitative but only qualitative. The meter and the pipes combined (yes you guessed it right) is the topic coherence pipeline. The four pipes are:
- Segmentation : Where the water is partitioned into several glasses assuming that the quality of water in each glass is different.
- Probability Estimation : Where the quantity of water in each glass is measured.
- Confirmation Measure : Where the quality of water (according to a certain metric) in each glass is measured and a number is assigned to each glass wrt it’s quantity.
- Aggregation : The meter where these quality numbers are combined in a certain way (say arithmetic mean) to come up with one number.
And there you have your topic coherence pipeline! There are surely much better analogies than this one but I hope you got the gist of it.
Coming to the technical stuff
Here’s an image of the topic coherence pipeline taken from the paper written by the people over at AKSW.
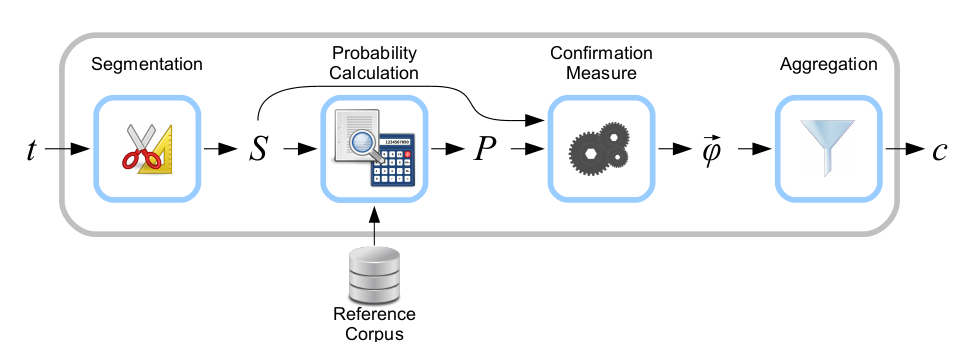
t : Topics coming in from the topic model
S : Segmented topics
P : Calculated probilities
Phi vector : A vector of the “confirmed measures” coming out from the confirmation module
c : The final coherence value
The API I have created works like this:
# The LDAModel is the trained LDA model on a given corpus. # The dictionary is the gensim dictionary mapping on the corresponding corpus. # The topics are extracted from this model and passed on to the pipeline. # I have currently added support for U_mass and C_v topic coherence measures (more on them in the next post). cm = CoherenceModel(model=LDAModel, corpus=corpus, dictionary=dictionary, coherence="u_mass") # To get the final coherence value simply type: cm.get_coherence()
You can find the full ipython notebook for the tutorial and example usage of this API here. In the notebook you can see how each coherence metric works and it’s output on different topic models depending on the human-interpretability of the topics they come up with.
Screenshot from the notebook
Each of the different pipeline components are coded as a different module within gensim/topic_coherence/. Rather than using the CoherenceModel, you can even plug in different components from the individual pipeline modules together manually to create your own coherence measures!
This week my pull request for including the topic coherence pipeline in gensim was merged. You can view the release note. This is in beta version right now so you can try it out. Please do complain on the mailing list! I’ll try to respond to all the problems to make this functionality better. Oh and the people who helped install the water pipeline are the brilliant people who are helping me solve all my problems while on this project. It’s been an absolute pleasure working with RaRe Technologies and gensim so far. Cheers!
