 RARE Technologies
RARE TechnologiesStarting with release 1.0.0, Gensim adopts semantic versioning.
The time went in a flash, but Gensim has reached maturity. It's been cited in nearly 500 academic papers, used commercially in dozens of companies, organized many coding sprints and meetups and generally withstood the test of time.

Between the continued Gensim support by our parent company, rare-technologies.com, and our open Student Incubator Programme, Gensim participating in the Google Summer of Code and regular meet-ups and coding sprints around the world, we felt it's time to move to "version 1.0.0".
Basically, Gensim is not a "fleeting academic/startup project" any more.
What changes in reality?
Nothing much, actually. Starting with Gensim 1.0.0, we're moving away from the old notation of 0.13.5 or 0.14.0 and adopting semantic versioning. All future releases will be in the format of MAJOR.MINOR.PATCH:
MAJOR version increments when we make incompatible API changes,
MINOR version when we add functionality in a backwards-compatible manner, and
PATCH version when we make backwards-compatible bug fixes.
And that's pretty much it.
It's still the same team, same roadmap, same mission of "topic modelling for humans". We continue to be focused on providing world-class unsupervised text analytics, with sane, performant implementations of carefully selected practical algorithms.
New features in Gensim 1.0.0
Apart from the cosmetic change in version numbering, 1.0.0 also brings you a bunch of new exciting functionality, plus a few deprecations.
Most notably:
Author-topic modelling. An extension of LDA with metadata. See how it compares Hinton's vs LeCun's papers in the NIPS corpus. Pure Python implementation by RaRe Incubator student Ólavur Mortensen.
WordRank, Facebook’s FastText and VarEmbed word embedding wrappers added by RaRe Incubator students Jayant Jain, Parul Sethi and Anmol Gulati. FastText and WordRank are useful on small datasets where FastText gives a high syntactic (“interchangeable words”) similarity and WordRank gives a high semantic (“is an attribute of”) similarity. FastText and VarEmbed consider parts of words so work even on unseen, out of vocabulary words. VarEmbed works particularly well for rare words.
scikit-learn Integration. Use Gensim’s LDA Topic Modelling in an sklearn classifier pipeline. A wrapper around Gensim's LdaModel now has fit and transform methods. See the SklearnWrapperLdaModel tutorial here. Added by RaRe Incubator student Aaditya Jamuar.
Python 3.6. You can now use Gensim in projects written in the latest release of Python. Added support for Python 3.6.
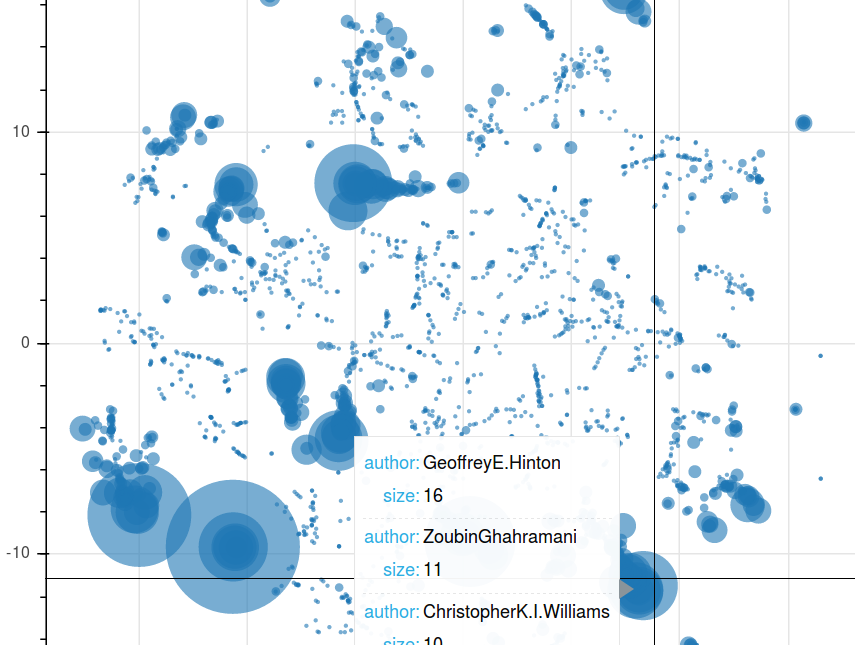
Authors of NIPS papers clustered by the topic of their papers.
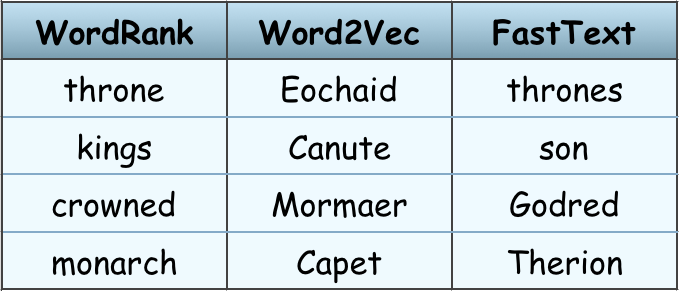
Words most similar to "King" in different word embeddings.
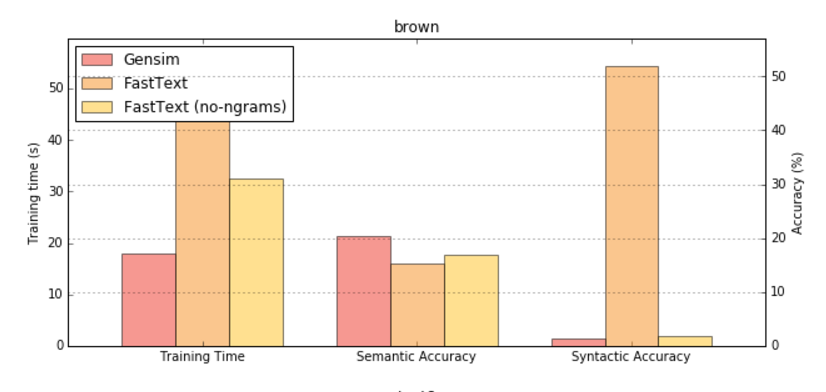
Great FastText success in finding interchangeable words when trained on the small Brown corpus.
And a few breaking changes in this release:
Direct access to word vectors in Word2vec class was deprecated. The properties were moved to a new KeyedVectors class. The reason for this deprecation is to separate word vectors from word2vec training. There are now many new ways to train word vectors outside of word2vec: WordRank, FastText and more coming soon.
Before upgrading to the 1.0.0 release please make sure that there are no deprecation warnings in your log when running the December 0.13.4.1 release. Use
model.wv.vocabinstead ofmodel.vocab, andKeyedVectors.load_word2vec_formatinstead ofWord2Vec.load_word2vec_format. More information in the release notes.Support for old Python versions 2.6, 3.3 and 3.4 has been removed. See discussion here. If you are using these old Python versions and need some bug fixes from the new 1.0.0 release, let us know on the mailing list and we'll see about backporting them.
Plus many other minor code and documentation improvements. Thanks to everyone who contributed. See ChangeLog for the full list. Enjoy!
