 RARE Technologies
RARE TechnologiesFacebook Research open sourced a great project recently – fastText, a fast (no surprise) and effective method to learn word representations and perform text classification. I was curious about comparing these embeddings to other commonly used embeddings, so word2vec seemed like the obvious choice, especially considering fastText embeddings are an extension of word2vec.
The main goal of the Fast Text embeddings is to take into account the internal structure of words while learning word representations – this is especially useful for morphologically rich languages, where otherwise the representations for different morphological forms of words would be learnt independently. The limitation becomes even more important when these words occur rarely.
I’ve used the analogical reasoning task described in the paper Efficient Estimation of Word Representations in Vector Space, which evaluates word vectors on semantic and syntactic word analogies. Word embeddings compared have been trained using the skipgram architecture.
Comparisons
The first comparison is on Gensim and FastText models trained on the brown corpus. For detailed code and information about the hyperparameters, you can have a look at this IPython notebook.
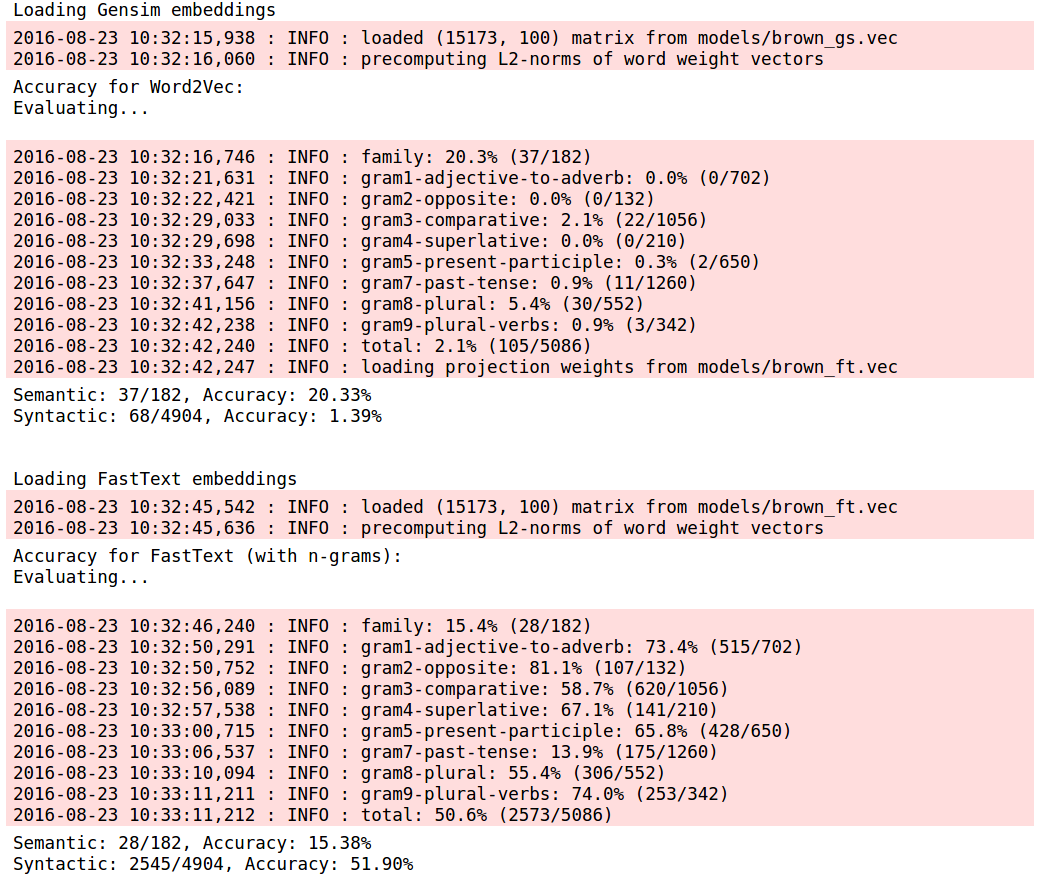
Word2Vec embeddings seem to be slightly better than fastText embeddings at the semantic tasks, while the fastText embeddings do significantly better on the syntactic analogies. Makes sense, since fastText embeddings are trained for understanding morphological nuances, and most of the syntactic analogies are morphology based.
Let me explain that better. According to the paper (Enriching Word Vectors with Subword Information), embeddings for words are represented by the sum of their n-gram embeddings. This is meant to be useful for morphologically rich languages – so theoretically, the embedding for apparently would include information from both character n-grams apparent and ly (as well as other n-grams), and the n-grams would combine in a simple, linear manner. This is very similar to what most of our syntactic tasks look like.
Example analogy: amazing amazingly calm calmly
This analogy is marked correct if:
embedding(amazing) – embedding(amazingly)
= embedding(calm) – embedding(calmly)
Both these subtractions would result in a very similar set of remaining ngrams. No surprise the fastText embeddings do extremely well on this.
Let’s do a small test to validate this hypothesis – fastText differs from word2vec only in that it uses char n-gram embeddings as well as the actual word embedding in the scoring function to calculate scores and then likelihoods for each word, given a context word. In case char n-gram embeddings are not present, this reduces (atleast theoretically) to the original word2vec model. This can be implemented by setting 0 for the max length of char n-grams for fastText.
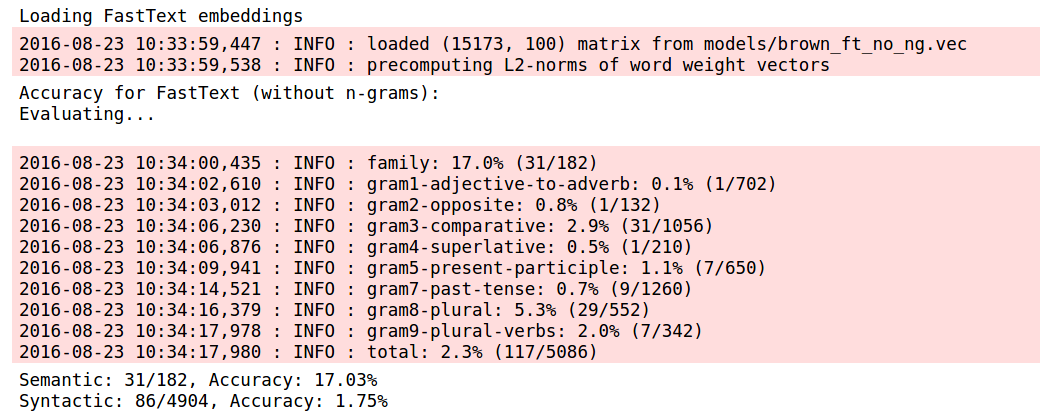
A-ha! The results for FastText with no n-grams and Word2Vec look a lot more similar (as they should) – the differences could easily result from differences in implementation between fastText and Gensim, and randomization. Especially telling is that the semantic accuracy for FastText has improved slightly after removing n-grams, while the syntactic accuracy has taken a giant dive. Our hypothesis that the char n-grams result in better performance on syntactic analogies seems fair. It also seems possible that char n-grams hurt semantic accuracy a little. However, the brown corpus is too small to be able to draw any definite conclusions – the accuracies seem to vary significantly over different runs.
Let’s try with a larger corpus now – text8 (collection of wiki articles). I’m also curious about the impact on semantic accuracy – for models trained on the brown corpus, the difference in the semantic accuracy and the accuracy values themselves are too small to be conclusive. Hopefully a larger corpus helps, and the text8 corpus likely has a lot more information about capitals, currencies, cities etc, which should be relevant to the semantic tasks.
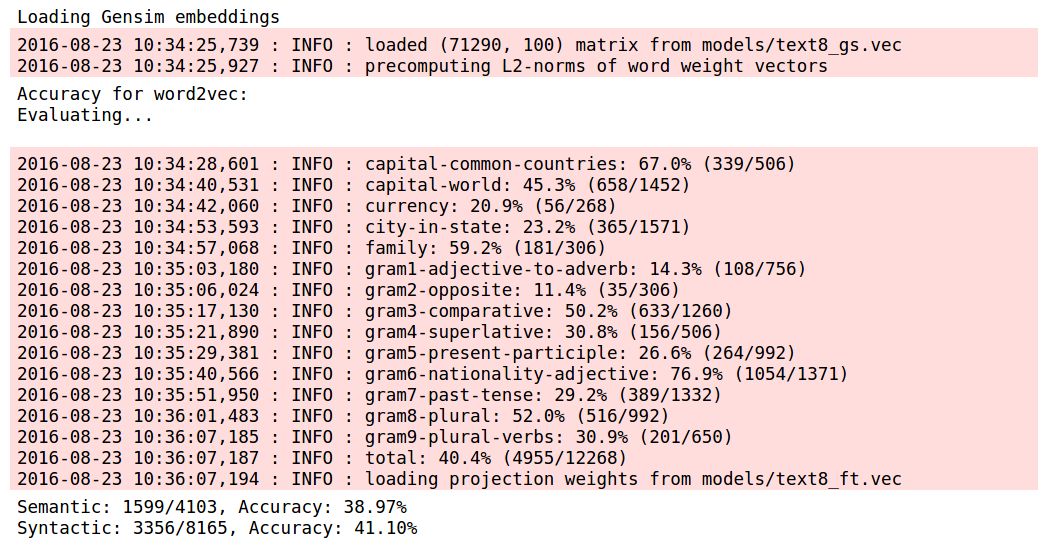
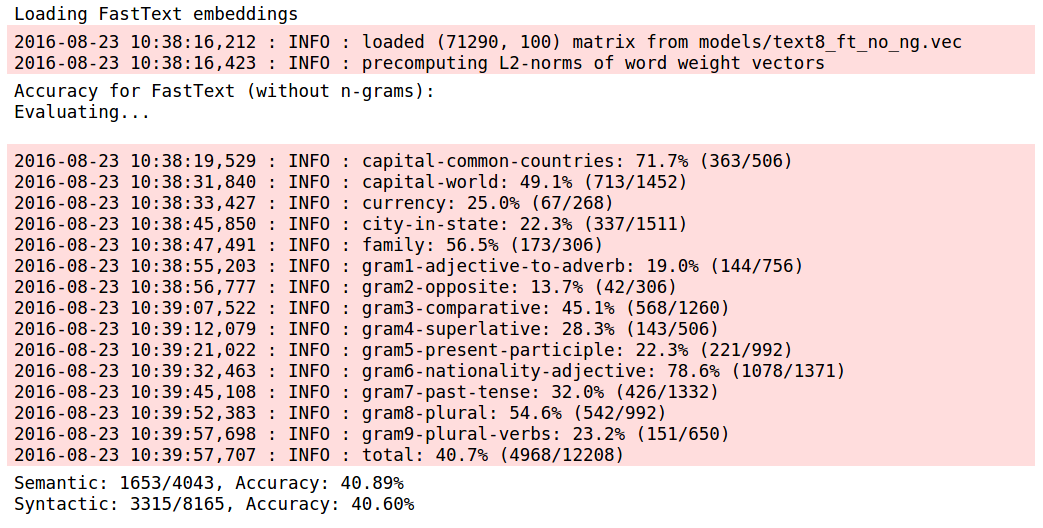
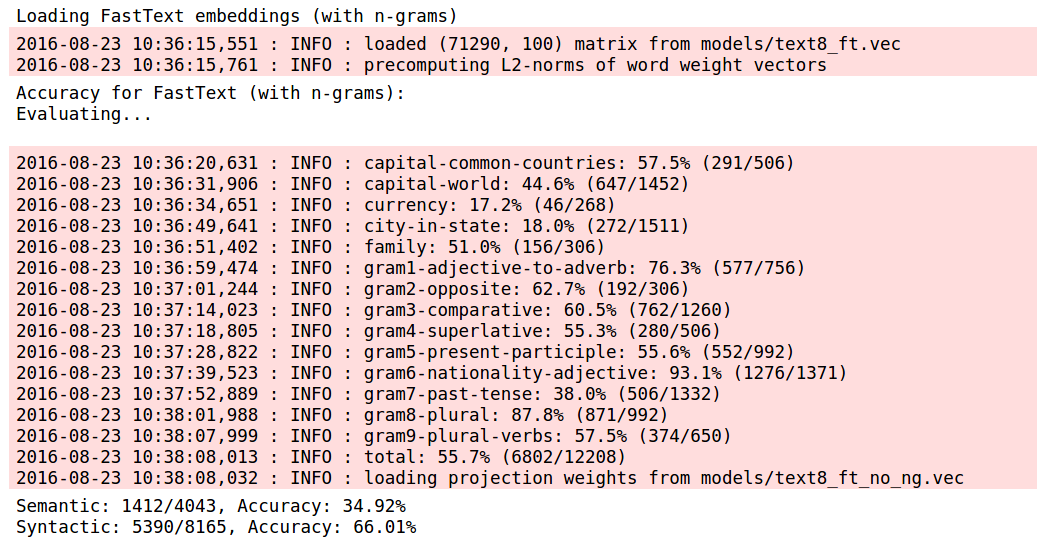 With the text8 corpus, we observe a similar pattern. Semantic accuracy falls by a small but significant amount when n-grams are included in FastText, while FastText with n-grams performs far better on the syntactic analogies. FastText without n-grams are largely similar to Word2Vec.
With the text8 corpus, we observe a similar pattern. Semantic accuracy falls by a small but significant amount when n-grams are included in FastText, while FastText with n-grams performs far better on the syntactic analogies. FastText without n-grams are largely similar to Word2Vec.
My hypothesis for semantic accuracy being lower for the FastText-with-ngrams model is that most of the words in the semantic analogies are standalone words and are unrelated to their morphemes (eg: father, mother, France, Paris), hence inclusion of the char n-grams into the scoring function actually makes the embeddings worse.
This trend is observed in the original paper too where the performance of embeddings with n-grams is worse on semantic tasks than both word2vec cbow and skipgram models.
Doing a similar evaluation on an even larger corpus – text9 – and plotting a graph for training times and accuracies, we obtain –
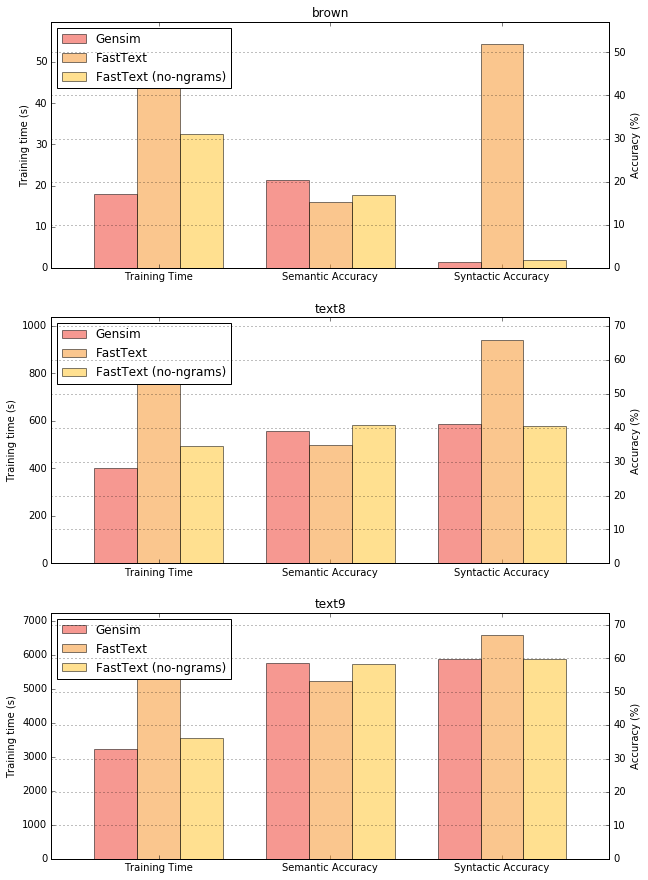
The results from text9 seem to confirm our hypotheses so far. Briefly summarising the main points –
- FastText models with n-grams do significantly better on syntactic tasks, because of the syntactic questions being related to morphology of the words
- Both Gensim word2vec and the fastText model with no n-grams do slightly better on the semantic tasks, presumably because words from the semantic questions are standalone words and unrelated to their char n-grams
- In general, the performance of the models seems to get closer with the increasing corpus size. However, this might possibly be due to the size of the model staying constant at 100, and a larger model size for large corpora might result in higher performance gains.
- The semantic accuracy for all models increases significantly with the increase in corpus size.
- However, the increase in syntactic accuracy from the increase in corpus size for the n-gram FastText model is lower (in both relative and absolute terms). This could possibly indicate that advantages gained by incorporating morphological information could be less significant in case of larger corpus sizes (the corpuses used in the original paper seem to indicate this too)
- Training times for gensim are slightly lower than the fastText no-ngram model, and significantly lower than the n-gram variant. This is quite impressive considering fastText is implemented in C++ and Gensim in Python (with calls to low-level BLAS routines for much of the heavy lifting). You could read this post for more details regarding word2vec optimisation in Gensim. Note that these times include importing any dependencies and serializing the models to disk, and not just the training times.
Conclusions
These preliminary results seem to indicate fastText embeddings are significantly better than word2vec at encoding syntactic information. This is expected, since most syntactic analogies are morphology based, and the char n-gram approach of fastText takes such information into account. The original word2vec model seems to perform better on semantic tasks, since words in semantic analogies are unrelated to their char n-grams, and the added information from irrelevant char n-grams worsens the embeddings. It’d be interesting to see how transferable these embeddings are for different kinds of tasks by comparing their performance in a downstream supervised task.
