 RARE Technologies
RARE TechnologiesMy second Google Summer of Code blog post is going to be a wee bit more technical – I’m going to briefly describe what topic models do, before linking to a tutorial I wrote which will teach you how to do some cool stuff with Topic Models and gensim.
Very, very briefly – given a collection of documents, topic models will help identify the topics which these documents are made from. What exactly is a topic? A topic is a collection of words. And each document is a collection of topics. Basically, if you’d want to figure out, say – 5 topics from the Harry Potter series of books, you might get the following 5 topics:
- The Muggle Topic – Muggle, Dursley, Privet, Arthur, Mudblood….
- The Voldemort Topic – Voldemort, Death, Horcrux, Snake, Dark…
- The Harry Topic – Harry, Scar, Quidditch, Gryffindor…
- The Quidditch Topic – Quidditch, Snitch, Broomstick, Krum…
- The Hogwarts Topic – Gryffindor, Dumbledore, House, Slytherin..
Mind you, a topic model won’t assign you a topic ‘label’, like I did. It’ll just spit out words which ideally semantically belong together and probabilities of them belonging to that certain topic. So, summing up – topics are sampled out of words, and documents are sampled out of topics.
If each chapter of a Harry Potter book is a document, then Chapter 1 of book 1 which introduced the Dursley family and had Dumbledore discuss Harry’s parent’s death would probably be broken up like – 40% Muggle topic, 30% Voldemort topic, and the remaining 30% would be probably be the Harry topic.
The topic model which I’m referring to for the rest of this post will be the most popular one in use now, the Latent Dirichlet Allocation model. To understand how this works, Edwin Chen’s blog post is a very good resource. This link also has a nice repository of explanations of LDA, which might require a little mathematical background. This paper by Blei is also a nice resource which sums up all the kinds of topic models which have been developed so far.
If you want to get your hands dirty with some nice LDA and vector space code, the gensim tutorial is always handy.
If you’ve briefly gone through and understood the above links and material, then the next part of the post will make sense – document coloring with LDA. Basically, after you’ve got your topics, it’s the process of coloring the words of the document depending on the topic they belong to.
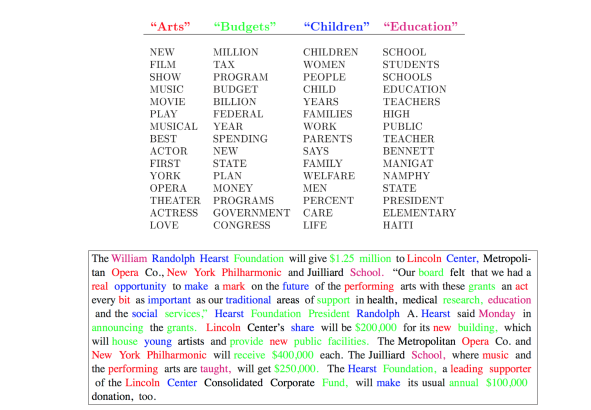
The image above is an example from the original Blei LDA paper.
The post will ‘continue’ with the tutorial I wrote for gensim as part of contributing towards my GSOC project. The link to the tutorial is here.![]()
Hope you enjoyed learning the basics of topic modeling and also got some code running! The tutorial was one of the pull requests merged in the last week – you can check out all the work in progress on the gensim github pull request page. My primary GSOC project still remains implementing Dynamic Topic Models, and it is a work in progress. Hopefully I can share a small working version of the same in my next GSOC 2016 blog post.
A huge shout out to Lev for being a brilliant and patient mentor and bearing with a lot of silly questions, and to Radim for always being on hand to review my code and ideas. It’s been a pleasure working with gensim and NumFOCUS so far!
