RARE Technologies
RARE Technologies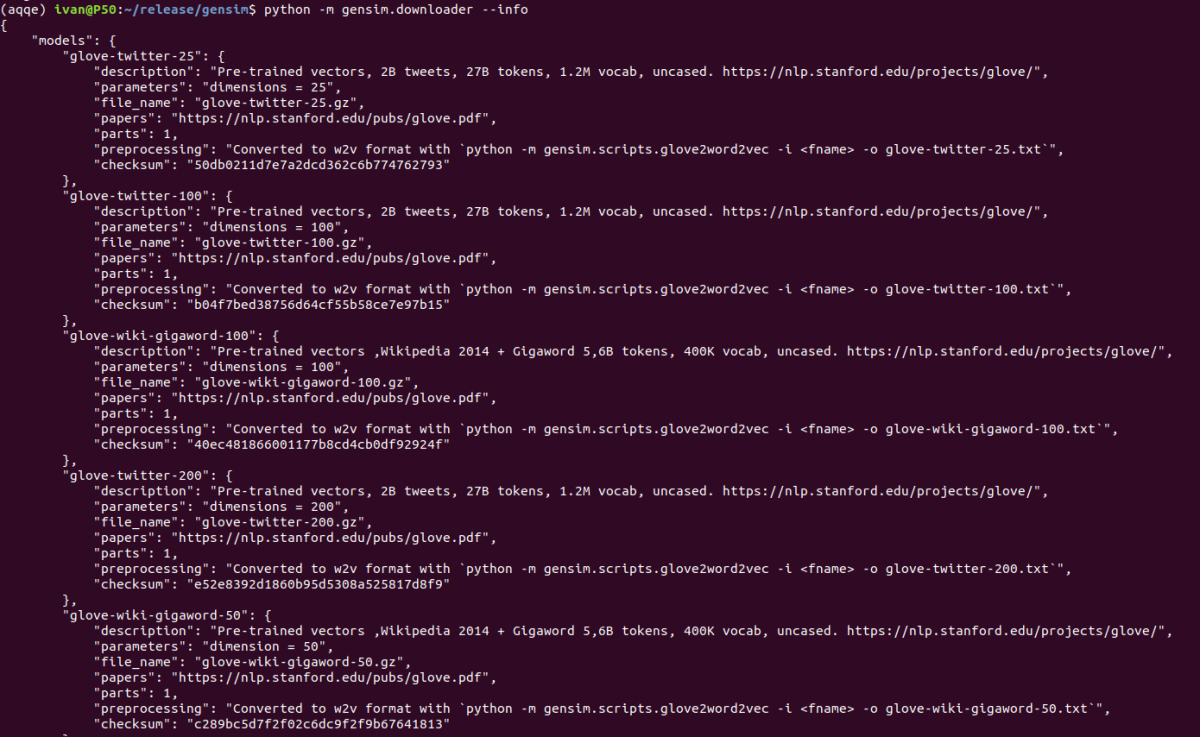
New download API for pretrained NLP models and datasets in Gensim
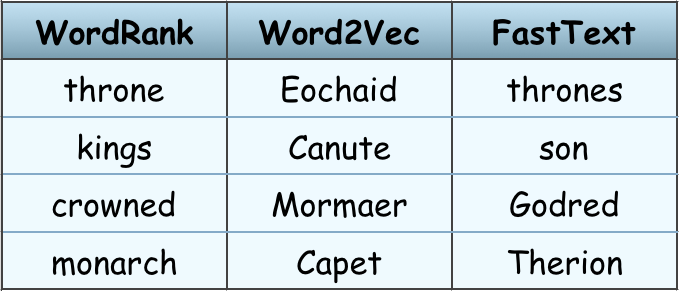
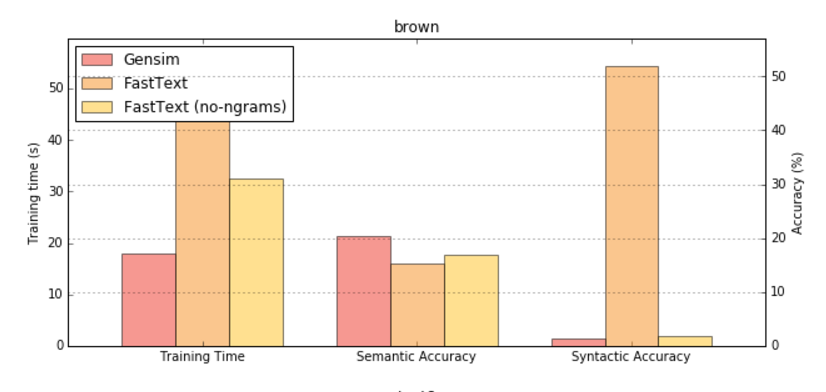
There’s no shortage of websites and repositories that aggregate various machine learning datasets and pre-trained models (Kaggle, UCI MLR, DeepDive, individual repos like gloVe, FastText, Quora, blogs, individual university pages…). The only problem is, they all use widely different formats, cover widely different use-cases and go out of service with worrying regularity. For this reason, we decided to include free …