 RARE Technologies
RARE TechnologiesThe final instalment on optimizing word2vec in Python: how to make use of multicore machines.
You may want to read Part One and Part Two first.
Multi-what?
The original C toolkit allows setting a “-threads N” parameter, which effectively splits the training corpus into N parts, each to be processed by a separate thread in parallel. The result is a nice speed-up: 1.9x for N=2 threads, 3.2x for N=4.
We’d like to be able to do the same with the gensim port.
In standard Python world, the answer to “multi-processing or multi-threading?” is usually “multiprocessing”. The reason is the so-called GIL aka global interpreter lock, which effectively enforces single-threaded execution for CPU-bound tasks, no matter how many threads you launch.
On the other hand, creating new processes with multiprocessing has its own issues. It works differently on Windows which is a maintenance headache, plus the way Python does it (fork without exec) can mess up some libraries. One such example is Apple’s BLAS on Mac (=the Accelerate framework with its “grand central dispatch”), as investigated here by none other than the machine learning guru Olivier Grisel. No matter where you go, ogrisel has been there first!
With word2vec, we’re already working with low-level C calls, so the GIL is no issue. I therefore decided to parallelize word2vec using threads, just like the original C toolkit.
One two three (not only you and me)
The original C tool assumes the training corpus resides in a file on disk, in a fixed format. Each thread will open this file and seek into its assigned byte position, splitting the file size evenly among the N threads. Then it starts parsing words from there, building sentences & training on the sentences sequentially:
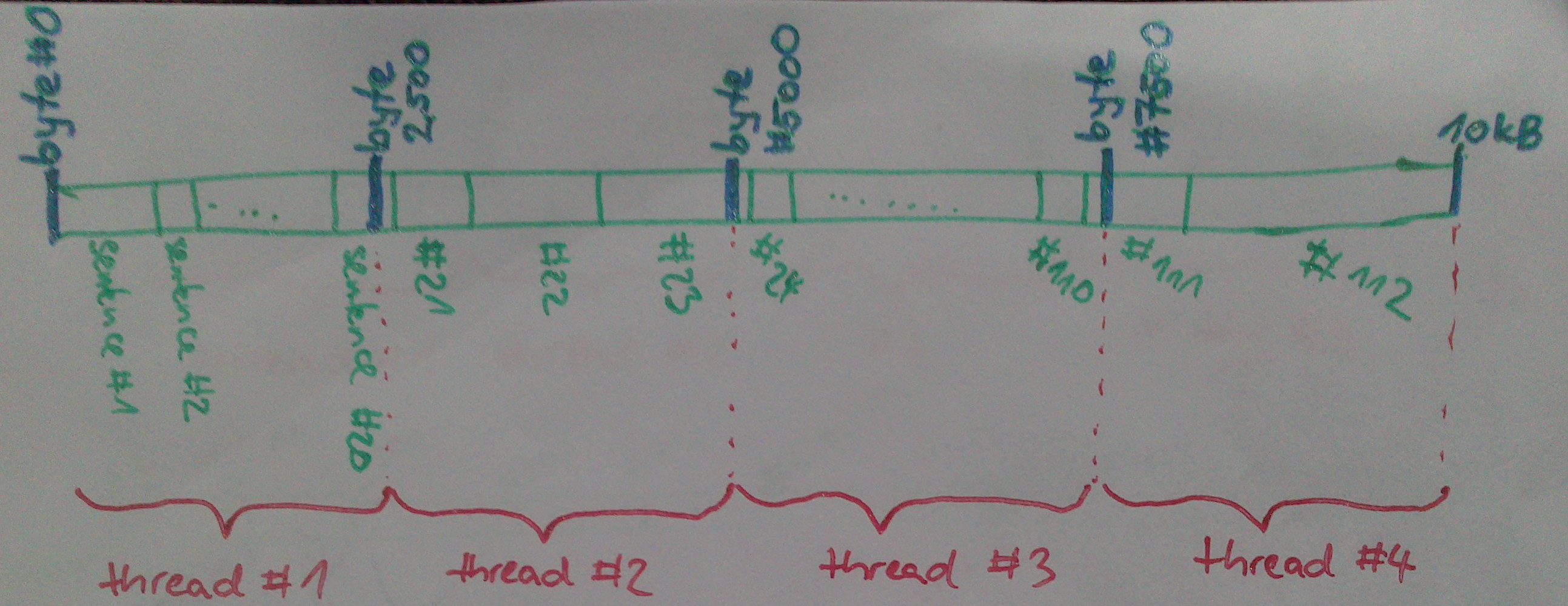
Dividing an input file into threads in the original C word2vec. Note that there are nasty edge cases, like initially seeking into the middle of a word, or a sentence.
A thread will process a fixed number of words (not bytes) before terminating, so if the word lengths are distributed unevenly, some file parts may be trained on twice, and some never. I personally think the I/O handling is not the prettiest part of the C word2vec.
The gensim word2vec port accepts a generic sequence of sentences, which can come from a filesystem, network, or even be created on-the-fly as a stream, so there’s no seeking or skipping to the middle. Instead, we’ll take a fixed number of sentences (100 by default) and put them in a “job” queue, from which worker threads will repeatedly lift jobs for training:
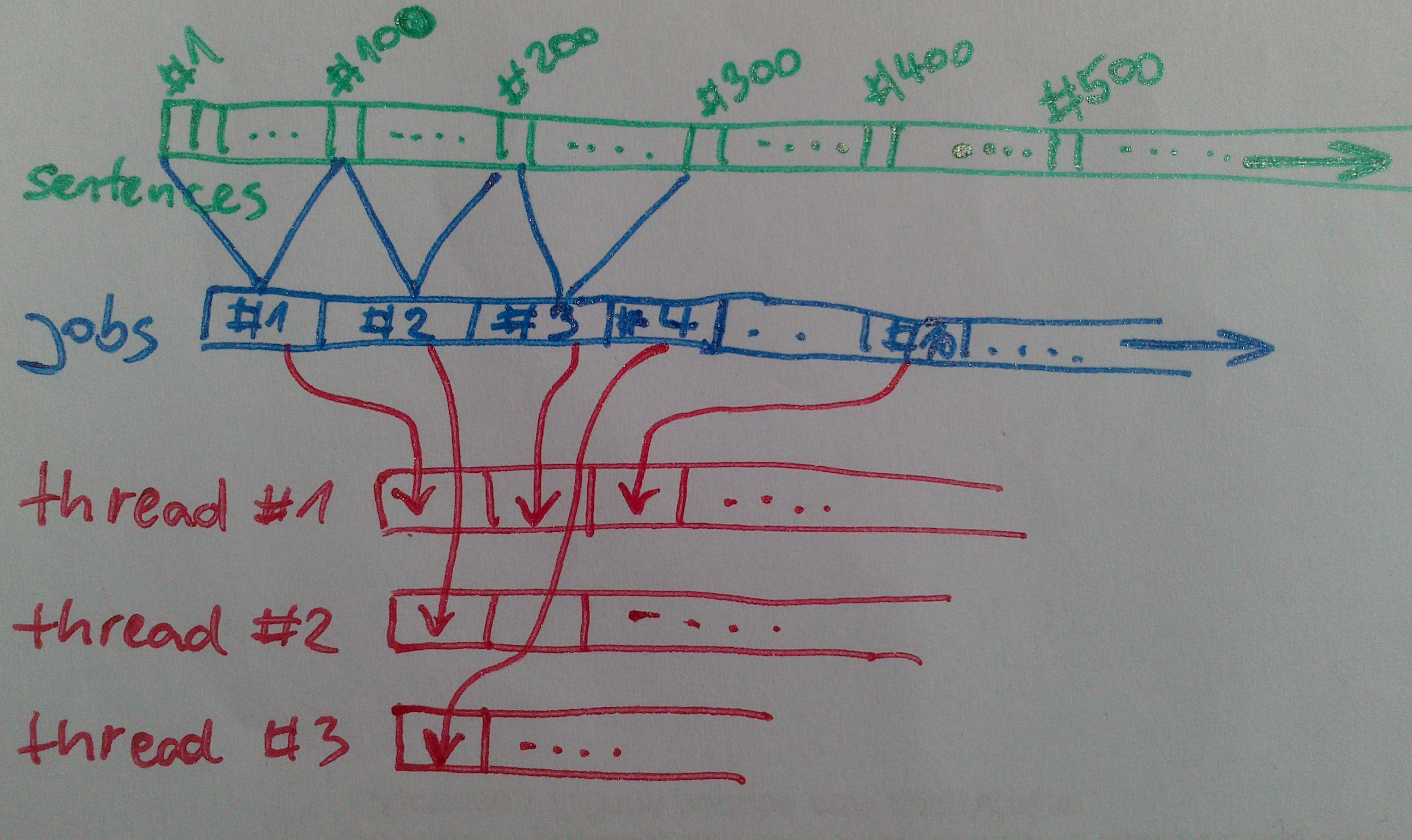
Chunking an input stream of sentences into jobs that are sent to threads, in gensim word2vec.
Python contains excellent built-in tools for both multiprocessing and threading, so adjusting the code to use several threads was fairly trivial. The final threaded code (logging omitted) looks like this:
def worker_train(job):
"""
Train model on a list of sentences = a job.
Each worker runs in a separate thread, executing this function repeatedly.
"""
# update the learning rate before every job
alpha = max(0.0001, initial_alpha * (1 - 1.0 * word_count / total_words))
# return back how many words we trained on
# out-of-vocabulary (unknown) words are excluded and do not count
return sum(train_sentence(model, sentence, alpha) for sentence in job)
jobs = utils.grouper(sentences, 100) # generator; 1 job = 100 sentences
pool = multiprocessing.pool.ThreadPool(num_threads) # start worker threads
word_count = 0
for job_words in pool.imap(worker_train, jobs): # process jobs in parallel
word_count += job_words
pool.close()
pool.join()
Interestingly, the producer/consumer pattern made the code clearer and more explicit, in my opinion. That’s already a plus, regardless of any speed-up.
The core computation is done inside train_sentence, which is the tiny function I optimized with Cython and BLAS last time. As I mentioned above, we must release the GIL for multithreading to be practical, and this is also done inside train_sentence, using Cython’s “with nogil:” syntax.
For the curious: in the original C word2vec, all threads access the same matrix of neural weights, and there’s no locking, so they may be overwriting the same weights willy-nilly at the same time. This is also true for the gensim port. Apparently this hack even has a fancy name in academia according to Tomáš: “asynchronous stochastic gradient descent”. But just to be sure, I measured the model accuracy for different numbers of threads below, too.
Timings
I’ll be measuring performance on the first 100,000,000 bytes of the English Wikipedia text, aka the text8 corpus. At 17,005,207 words, it’s about 17x larger than the Brown corpus I used in Part II. The reported speed is in “words per second” again, taken from the best of three runs. Accuracy is computed on the questions-words.txt file that comes with the original C word2vec:
| # worker threads (speed/peak RAM/accuracy) | ||||
|---|---|---|---|---|
| implementation | 1 | 2 | 3 | 4 |
| C word2vec | 22.6k / 252MB / 27.4% | 42.94k / 252MB / 26.4% | 62.04k / 252MB / 26.8% | 72.44k / 252MB / 27.2% |
| gensim word2vec | 109.5k / 591MB / 27.5% | 191.6k / 596MB / 27.1% | 263k / 592MB / 27.3% | 311.7k / 601MB / 28.2% |
In other words: 2 threads equal a 1.75x speed improvement, 4 threads 2.85x, compared to one thread. This is worse than C’s respective 1.9x and 3.2x, presumably because of all the thread-safe job queueing that happens in Python.
I’m not sure why the original C toolkit has slightly inferior accuracy results than that Python port though. The input, the algorithm and the evaluation process are exactly the same. It may have to do with the different way the training corpus is split among threads and therefore there are different collisions. Or with its random number generation… or the I/O parsing. Working with text in C is no fun and fairly error prone. I don’t have time (nor will) to reconstruct and replicate the C code that deals with I/O, but if you have an idea, let me know in the comments.
I was naturally interested in how the accuracy improves with
Memory
During this optimization series, I didn’t talk about memory yet. How much memory does the Python port need, especially compared to the original C code?
Python has a reputation of being memory intense… which is completely true. It contains its own memory manager, so there’s no control over how much memory something really consumes. For example, the above model built on text8 needs ~280MB, roughly the same as the C code. But Python over-allocates and creates temporary copies during training, never to return this memory back to the OS until the process exits, even when the memory’s not needed anymore. So the actual RAM footprint, as OS X sees it, is more than double that, ~600MB.
The good news is, this memory footprint is constant, regardless of how large the training corpus is. This is true both for the C toolkit and for the Python port. Only a small, fixed number of sentences is loaded and held in RAM at any one time.
Summary
With hyper-threading (“fake” 8 cores on my quadcore i7 MacbookPro), Cython-optimized hotspot loop, BLAS and all the other optimizations, the best result I got was 44 seconds, or 378k words/s, on the text8 corpus. Compared to the initial implementation in NumPy, which took several hours at 1.2k words/s, and even to the 91k of the original C tool on the same setup, this is a substantial improvement and a reason to rejoice!
As this is the third and final blog on word2vec, I’ll conclude with a few practical points:
-
Where: The code lives inside gensim, release >= 0.8.8. Installation instructions. Don’t forget to install Cython too (pip install cython), to make use of all the optimizations described here.
-
How: Documentation & API reference: gensim website. From Python shell, use standard docstrings: help(gensim.models.word2vec) etc. For the great and ever-improving IPython: gensim.models.word2vec?. I also added a simple command line example: when you run python -m gensim.models.word2vec text8 questions-words.txt, a model will be trained and its accuracy evaluated, with the log telling you what’s happening. Use as a template.
-
When: These blog posts always reflect the gensim code at the time of writing. To go back in time to check out an older version/replicate older results, use the git versioning.
I have to say these were pleasantly spent 3 weekends. It’s fun to go back to the roots and just optimize stuff, without any care for business and management 🙂 Of course, I have to thank Tomáš Mikolov and his colleagues, who did all the hard work so that people like me can play around. I hope they publish a new, improved algorithm soon — with all the scaffolding done, a Python port should be much simpler next time.
(If you liked this series, you may also like this word2vec tutorial and benchmark of libraries for nearest-neighbour (kNN) search.)

Comments 21
Does the python package support phrases ?
Author
If you mean “support” like in the C package (=pre-generate some bigrams based on word frequencies, then use the same training algo): you can add that in four lines of Python, if you really need it.
If you mean a proper, theoretical support for training longer structures (=not present in the C package): no, this is just a port. No new functionality yet.
But I think this is what Mikolov & co are actively working on, so despair not…
Hi Radim, This is really cool work! Just wondering when the next version of gensim that contains these changes will be released?
Mark
Author
Hi Mark. It’s ready as such, but I want to write a tutorial first.
Or you can write one, to speed up the process 🙂 Using whatever scenario shows word2vec in action, step by step.
Hi Radim,
Nice write up! That your code is nearly x5 faster than the C code is surprising and impressive. Why do you think this is? Of course, you’ve also optimized the hot loops by rewriting them in Cython (essentially C) — is it the linking to BLAS that really helps? If you wanted to similarly speed up word2vec in C, what would you do differently?
Thank you!
chris
Author
Hi Chris, good to hear from you! Yes, it’s mostly the optimized BLAS routines vs. generic C code. With a good compiler + compiler settings + a disassembly check, the C code will do ±same.
Another option is to link the C word2vec against BLAS too. I posted such a patch here: https://groups.google.com/d/msg/word2vec-toolkit/e4X-9iQWmLY/5lSUsxFrpxYJ
Thanks Radim, awesome!
Hello!
I tried using your patch for word2vec.c and for some reason got no increase in speed, the results were almost identical. Could you tell me what may be going wrong?
I am working on OS X 10.10.5 and trying to link the code against Apple’s vecLib BLAS.
This is the change I made to the makefile:
word2vec : word2vec.c
$(CC) word2vec.c -o word2vec $(CFLAGS) -I /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/Headers -framework Accelerate
Author
What word2vec parameters are you using?
That patch only added BLAS to some code paths (only hs skip-gram, IIRC). Are you using that combination of options?
For other combinations, you can make analogous changes to the code, replacing for-loops with BLAS calls.
It’s also possible you’re using a better compiler, so the difference between GCC and BLAS is not as large anymore…
Let me know which one is the case.
Thank you for your answer!
The first time I was using the parameters from demo-word.sh:
word2vec -train text8 -output vectors.bin -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 1 -iter 15
Then changed the parameters to:
word2vec -train text8 -output vectors.bin -cbow 0 -size 200 -window 10 -negative 0 -hs 1 -sample 1e-4 -threads 20 -binary 1 -iter 15
Did I get it right?
Now the BLAS version is about x2 faster:)
Hi Radim,
your code is so beautiful and helpful
when i practice your example and something puzzle me:
1) 、TypeError: train_sentence() takes exactly 4 positional arguments (3 given)
so i changed it to:
train_sentence(model, sentence, alpha, work)
What is the meaning of the fourth parameter?
2)、Traceback (most recent call last):
File “train.py”, line 30, in
for job_words in pool.imap(worker_train, jobs): # process jobs in parallel
File “/usr/local/python-2.7/lib/python2.7/multiprocessing/pool.py”, line 589, in next raise value
AttributeError: ‘str’ object has no attribute ‘syn0’
what‘s the meaning of the error?
environment:
python 2.7
gensim-0.8.8
Cython-0.19.2
scipy-0.13.2
numpy-1.7.2rc1
Author
Hi Leo, you’re better off using the current word2vec gensim code, rather than copy-pasting this old example which calls into the new gensim code (mismatch). The example uses gensim as it was when I was writing this blog post, but gensim has changed since (new optimizations).
To answer your questions:
1. “work” is an array of temporary memory. It is passed as a parameter so that it doesn’t have to be allocated again and again inside each function call (=slow).
2. sounds like you’re passing a string object where a model object is expected. Not sure where or why.
Thank you very much Radim
So would it take 6 hours to process the whole English wikipedia corpus ?
A few questions : how many features ? what’s your window size (it changes a lot of thing) ? Also what’s your vocabulary size ? I’m suspecting the vocabulary is relatively smaller (if I remember correctly, 10% of wikipedia has a 500k words vocabulary, while full wikipedia has 2.5M words)
Author
Same params as the original word2vec demo script: size 200, window 5, min count 5…
The effect of these parameters on performance is fairly predictable, so it actually doesn’t change a lot of things.
I checked the trained models for you and text9 uses 218,316 word types, text8 71,290 word types. Hope that helps!
nice post
Hi Radim,
I am using GENSIM in Linux Ubuntu. I installed Cython, Atlas, Pyro4 and the last thing was GENSIM. I tried GENSIM via PIP and also pulling from Github and setup.py install.
from gensim.models import word2vec
word2vec.FAST_VERSION tells me 1
gensim/test/test_word2vec.py runs at 100K words/s, but my own test runs at 20K words/s. I think is quite slow given that test_word2vec.py runs with workers=2, whereas mine is workers=32. In fact, workers=1 at runs at same speed. “logging” shows that the training is running with the set number of workers, no Warning of no detecting C compiler as I got in other Linux machine.
The same training vocabulary and setting ran on the C version of Word2Vec takes 1/3 of the time than GENSIM.
Is there anything that I am missing in my installation that could be causing GENSIM no to run faster in parallel?
Many thanks in advance for your attention.
Best regards
Harvy
Author
Hello Harvy,
I see two possible explanations:
1) the thread that prepares input jobs for the workers isn’t fast enough; the workers are starved for input (possible, since you have so many workers). How fast is your input sentence generation?
2) the overhead of Python is simply too large with so many threads. Each worker runs in optimized C, but it has to report results back to Python. With so many workers, the overhead could be a bottleneck.
Let me know if you’ve managed to find whether the slowness is due to 1) or 2).
We’re actually planning some optimizations around larger job batching, which would help alleviate 2). If it’s 1) though, there’s not much we can do — C word2vec seeks into a part of the input file with each worker, which we cannot do with gensim’s streamed version.
Hi Radim,
I am training the model with either a list of words or list of lists, where each sublist contains a sentence or line of words. I am not using any corpus to generate the sentences. Can this be the problem?
To assess 2), I tried the same code with less workers, e.g. 2 but still runs equally slow. As mentioned before, the code runs as fast as using one thread.
It has taken me a while to reply because I have also tried setting up everything in Windows 10. However, frustrations levels went up. Python 2.7.10 (Anaconda or X,Y) required me to have Atlas. Atlas for windows is a pain to compile via cygwin. I uninstalled all of them and I am going to install a PythonXY 2.7.5. as is the same version running in my Linux server.
Do you think there is anything wrong in the way I am installing the packages?
Thanks for your support.
Harvy
Author
Hello Harvy,
I’m not sure how to read “training the model with either a list of words or list of lists”. Training on a list of words won’t even work — the API expects a list of sentences.
Blog comments are not the ideal medium for this discussion — probably best if you can post this to the gensim mailing list, or a GitHub issue.
Either way, please include a concrete description of your setup (what exactly you’re doing, exact package versions etc), as well as a copy of the log from your training run.
Pingback: Getting started with Word2Vec | TextProcessing | A Text Processing Portal for Humans