 RARE Technologies
RARE TechnologiesThe end of the year is proving crazy busy as usual, but gensim acquired a cool new feature that I just had to blog about. Ben Trahan sent a patch that allows automatic tuning of Latent Dirichlet Allocation (LDA) hyperparameters in gensim. This means that an optimal, asymmetric alpha can now be trained directly from your data.
Asymmetric Dirichlet Priors
What is that good for? Asymmetric priors are reported to lead to better fitting models (sounds naughtier than it is!).
This means more natural looking LDA topics, because we expect certain groups of words (topics) to be occurring more frequently in documents, and the model can now account for that by learning a non-uniform Dirichlet prior (base measure + concentration). Now this is the prior for “topics in document” distributions, called alpha — there’s another Dirichlet prior in LDA, called eta, which controls the “words in topic” distributions. Using asymmetric eta is reported to give worse results though, so it’s not part of this patch and gensim uses a simple uniform base measure there.
Well, that’s basically it. I would have announced this on the mailing list, except I also want to include an example that will be easier to do in HTML & Javascript:
| topics 1-50 | topics 51-100 | ||
|---|---|---|---|
| asymmetric alpha model | symmetric model alpha=0.01 | asymmetric alpha model | symmetric model alpha=0.01 |
| march, february, january, december, november | june, april, march, february, january | group, air, force, flight, wing | air, force, flight, wing, training |
| two, first, three, second, four | first, two, three, year, day | black, text, color, green, bar | black, red, white, blue, green |
| history, century, years, first, early | century, history, early, first, years | species, logs, found, links, family | species, family, found, genus, plant |
| david, michael, smith, john, tom | david, michael, john, paul, smith | french, france, paris, jean, des | french, france, paris, saint, jean |
| list, see, articles, lists, related | list, articles, related, note, see | park, national, area, site, forest | park, river, lake, mountain, area |
| born, family, life, died, son | born, years, life, first, career | art, museum, arts, artist, gallery | art, arts, artist, work, artists |
| time, said, request, block, first | policy, request, block, dispute, account | red, white, blue, boston, massachusetts | top, big, model, ten, fashion |
| article, sources, page, source, notable | talk, article, sources, think, don | english, language, languages, words, translation | english, language, nom, word, words |
| south, north, west, east, australia | south, north, west, east, western | river, lake, bridge, valley, creek | station, road, line, route, railway |
| new, york, chicago, city, jersey | new, york, boston, city, jersey | music, major, dance, piano, musical | music, major, dance, piano, musical |
| talk, discussion, page, made, debate | talk, page, discussion, made, please | party, election, political, vote, votes | party, election, elected, democratic, votes |
| john, william, george, james, thomas | john, william, george, james, london | police, death, killed, people, crime | police, killed, said, death, people |
| book, published, books, press, author | book, editor, published, books, editing | paul, saint, mary, peter, joseph | christian, god, temple, religious, religion |
| name, created, term, names, nom | name, title, unknown, names, reason | series, characters, character, man, story | game, games, play, card, series |
| talk, don, think, just, like | like, get, just, time, thanks | women, men, female, male, sex | women, men, female, male, start |
| june, april, rev, parish, dates | church, rev, importance, catholic, bishop | summer, ice, winter, storm, wind | summer, ice, winter, wind, storm |
| community, members, organization, public, groups | project, community, development, program, support | island, van, bay, dutch, islands | island, bay, coast, sea, islands |
| company, http, business, companies, inc | company, business, companies, industry, inc | canada, minister, canadian, prime, ministry | empire, war, emperor, battle, ali |
| project, work, process, new, help | number, time, different, two, level | station, line, route, railway, closed | ship, war, navy, ships, returned |
| university, research, college, science, professor | university, college, professor, degree, academy | order, cross, flag, arms, knight | order, grand, cross, master, golden |
| best, series, links, external, director | best, director, festival, directed, actor | space, star, light, sun, earth | light, space, sun, earth, moon |
| president, member, served, office, committee | president, government, minister, council, general | food, fish, wine, seeds, tea | food, fish, apple, tea, meat |
| district, city, town, province, area | city, district, province, rural, region | temple, god, lord, spirit, religious | writer, works, prize, short, literature |
| user, link, links, additions, mentioned | user, link, additions, list, links | free, copyright, commons, fair, original | file, image, quality, images, copyright |
| round, final, world, won, event | round, team, final, won, cup | water, energy, power, oil, gas | water, energy, power, oil, gas |
| united, states, florida, carolina, kingdom | united, states, kingdom, america, bush | season, team, coach, year, conference | group, members, association, groups, national |
| love, night, little, girl, man | song, band, released, music, single | india, indian, portuguese, colony, state | india, indian, china, chinese, lee |
| league, club, team, cup, played | season, team, league, club, played | center, health, medical, hospital, children | health, medical, children, hospital, care |
| british, london, england, ireland, irish | county, ireland, england, wales, irish | china, japan, chinese, japanese, lee | japan, japanese, dan, dream, imperial |
| international, country, republic, world, russian | world, international, australia, european, country | gold, silver, bronze, iron, mine | gold, silver, bronze, mine, iron |
| song, band, released, music, track | series, show, season, special, shows | file, image, quality, images, picture | type, body, human, cell, cells |
| american, born, america, african, refer | american, born, canada, british, canadian | hill, mountain, mount, range, mountains | research, science, journal, theory, studies |
| building, house, built, buildings, historic | building, built, buildings, tower, stone | church, christian, catholic, bishop, pope | italian, italy, roman, rome, maria |
| school, high, students, schools, education | school, high, students, schools, education | human, cell, effects, body, study | system, systems, information, computer, network |
| left, right, hook, runs, test | right, back, left, made, runs | title, empire, vol, emperor, kingdom | car, engine, test, driver, speed |
| news, show, day, week, channel | news, local, event, newspaper, notable | date, unknown, roman, latin, victor | spanish, del, spain, juan, portuguese |
| data, local, software, entry, web | see, page, pages, mentioned, data | stage, tour, theatre, play, poetry | johnson, morris, francis, stuart, ruth |
| back, get, story, tells, mother | man, character, characters, story, novel | italian, italy, greek, maria, rome | greek, alexander, greece, bin, philip |
| system, time, number, two, size | design, designed, two, version, first | horse, cat, dog, animal, bear | old, horse, dog, cat, animal |
| county, state, washington, virginia, ohio | state, county, washington, chicago, virginia | army, general, military, division, service | star, iii, stars, generation, luke |
| false, theory, social, people, political | people, false, view, self, political | involved, interest, rule, calculated, haar | rules, rule, gets, sum, infinite |
| desk, box, made, top, head | field, surface, ring, plate, angle | race, car, engine, model, design | race, present, run, track, course |
| million, bank, money, financial, government | million, bank, money, government, financial | type, fire, gun, machine, action | links, http, external, site, official |
| people, village, total, population, land | town, village, land, area, castle | ship, navy, war, world, ships | jewish, israel, arab, camp, egypt |
| law, court, act, case, legal | law, court, act, rights, legal | class, importance, low, start, changed | class, renamed, classes, added, group |
| war, battle, forces, army, military | war, army, military, general, battle | field, texas, georgia, louisiana, austin | african, south, georgia, africa, florida |
| san, california, los, mexico, spanish | san, california, texas, los, mexico | jewish, israel, ali, arab, egypt | van, dutch, netherlands, jan, holland |
| german, germany, von, der, berlin | german, russian, germany, von, der | game, games, card, play, cards | brown, wine, glass, oak, beer |
| road, street, highway, avenue, centre | house, museum, street, center, historic | sign, loss, call, submission, bin | feb, nov, dec, oct, sat |
| king, queen, prince, castle, royal | son, king, family, daughter, married | page, special, jan, feb, nov | hook, orange, bears, cave, tiger |
If you hover over a topic, it will highlight the closest topic from the other model in red (closest = topic with the smallest Hellinger distance). So placing your mouse over a topic from symmetric alpha (columns 1 & 3) will highlight the closest topic from asymmetric alpha model (columns 2 or 4). I tried to fit as many topics on screen as possible, because some highlighted hits may be quite far apart. There’s probably a better way to visualize this 🙂
For many topics there is a 1:1 correspondence between the two models, but for others, a single topic may be “the nearest” for several topics from the other model, and vice versa. In other words, topic A may be the nearest for topic B, but the nearest for topic B may be a different topic C (=the “nearest” relationship is not symmetric). I highlighted these “unusually matching” topics in light red in the table above. Other than that, skimming the table, I don’t see much difference in terms of topic quality on this particular dataset, although the perplexity was slightly lower for the asymmetric model.
I used the bag-of-words Wiki corpus of ~3.7 million documents generated in the previous blog post for training, except I restricted its vocabulary to the 7,702
words from Matt Hoffman’s original onlinelda code:
lda = gensim.models.LdaModel(vocab_filter[mm], id2word=dictionary, alpha='auto')
As you can see, this vocabulary filtering was streamed online, one vector at a time, so I didn’t have to recreate/store the entire Wiki corpus again. Check out the FAQ if you want to do similar transformation tricks in gensim.
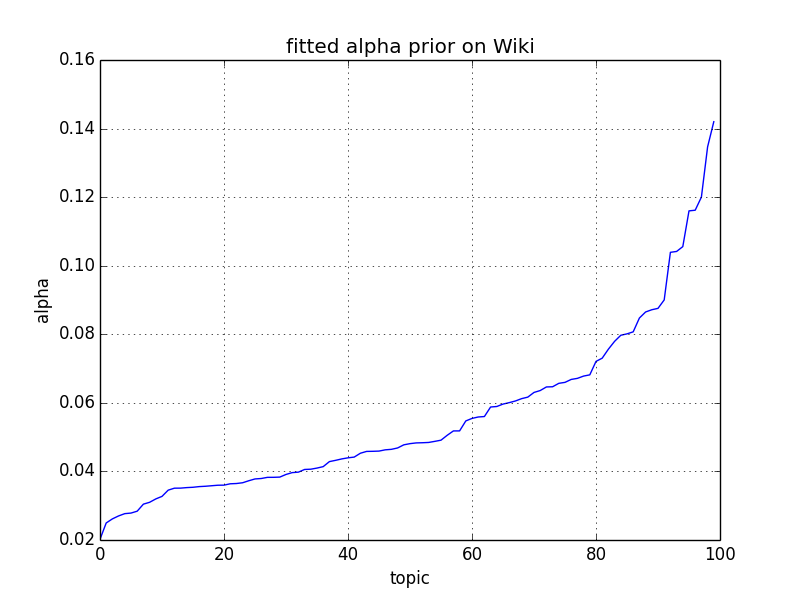
Alpha values fitted on the Wikipedia corpus using 100 topics.
LDA perplexity estimates
I also improved reporting of model perplexity while I was at it. In the log, you’ll see lines like
INFO : -6.778 per-word bound, 109.7 perplexity estimate based on a held-out corpus of 386 documents with 18342 words
after every ten mini-batch updates (configurable).
This means that gensim took the current mini-batch and estimated perplexity based on the adjusted variational Evidence Lower BOund (ELBO), on this held-out corpus. The “adjusted” bit means that likelihood is re-weighted as if the held-out corpus was the entire training corpus. This is done to make comparisons between models using a different number of topics/model settings easier, as ELBO also includes model regularization parts that can otherwise dominate the score.
This held-out perplexity is an estimate, so different mini-batches will give different scores. But in general you’ll see the perplexity value decrease as training progresses.
The patch has been merged into gensim’s develop branch and will be part of the next stable release. Big thanks to Ben & happy holidays to everyone!

Comments 2
The FAQ link is broken https://github.com/piskvorky/gensim/wiki/Recipes-&-FAQ#q8-how-can-i-filter-a-saved-corpus-and-its-corresponding-dictionary
Would you be willing to post the code for this blog post? I’m specifically interested in the Hellinger distance comparison between topics across models.