RARE Technologies
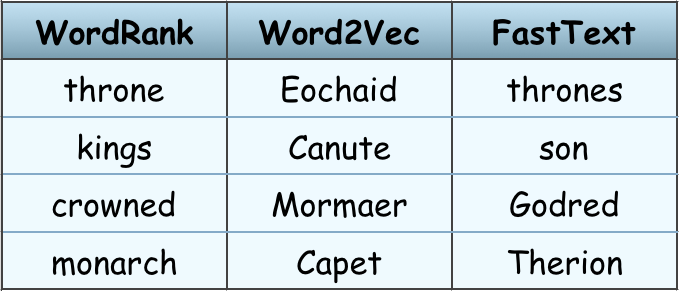
RARE TechnologiesJuly 20, 2017 This week, I’ve mostly worked on implementing native unsupervised fastText (PR #1482) in gensim. It’s quite challenging as I had to look into the fasttext C codes, and read the research paper to properly understand how this is working, and then had to figure out the similarity with word2vec code. After lots of discussion with mentors, we …