 RARE Technologies
RARE TechnologiesWord2Vec became so popular mainly thanks to huge improvements in training speed producing high-quality words vectors of much higher dimensionality compared to then widely used neural network language models. Word2Vec is an unsupervised method that can process potentially huge amounts of data without the need for manual labeling. There is really no limit to size of a dataset that can be used for training, so the improvements in speed are always more than welcome.
In recent years we have seen a renaissance in the areas of deep learning, which came hand in hand with new advancements in hardware. GPUs in particular have become a vital part in the process of training of deep neural network models. They bring a nice speed-up parallelizing the computation of chains of matrix products.
Gensim’s Word2Vec is parallelized to take the advantage of machines with multi-core CPUs. Having a GPU at our disposal, it sure will be worth taking an advantage of its resources and speed up Word2Vec’s training even more.
I decided to explore the Word2Vec algorithm and look at an option to use the GPU for training as part of The RaRe Technologies Incubator Program because I wanted to learn more about language models and word embeddings in general.
There is a working library by niitsuma called Word2veckeras, available on PyPI as a package for download. Built on top of Gensim’s Word2Vec it supports both CBOW and skip-gram models, which are written in Keras. A Doc2Vec implementation is included, too.
Keras is a really cool and handy library that makes the process of implementing various different neural network models fast and easy. You can try different ideas and get results quickly. I enjoyed working with Keras before on different time series prediction tasks using recurrent neural networks. Keras is running on Theano/Tensorflow back-ends, libraries that are both designed to harness the power of GPUs. You can very simply switch between the back-ends and the use of CPU or GPU.
I started by rewriting the Keras models in Word2veckeras into the current Keras version using it’s functional API. This solved the compatibility issues that arose from an old graph model used in previous Keras versions. When I was done I began testing Word2veckeras package comparing it’s speed with the Gensim’s implementation.
Using only my laptop’s CPU at first, Gensim was running about 80 times faster. I set up a g2.2xlarge instance on Amazon’s cloud with an 8 core Intel Xeon and Nvidia GRID K520 GPU and kept on testing thinking that GPU would speed-up the dot product and backpropagation computations in Word2Vec and gain advantage against purely CPU powered Gensim. Here is an installation tutorial for the image in case you would like to reproduce my results.
It surprised me that Word2veckeras CBOW training on Theano with the aid of CNMeM and cuDNN revealed that the processing of each epoch on Brown corpus was now around 200 times faster with Gensim compared to a GPU powered Word2veckeras. I tried feeding in different batch-sizes to Word2veckeras with speed being relatively similar. Except for the batchsize both Gensim’s Word2Vec and Word2veckeras used the same parameters.
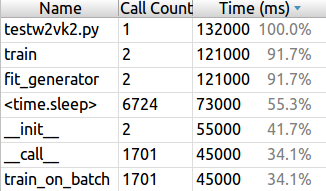
program goes to sleep for over 55% of total runtime to wait for the training data to form

the training data queue fills up again during the sleep and the training can continue
Now, how to make Word2veckeras faster? After performing some profiling tests on my machine I discovered a major bottleneck taking place during the data preprocessing step. The Keras model training had to halt for over 50% of total run time on Brown corpus, because the data queue coming from the generator frequently emptied and needed extra time to fill up by the new preprocessed data samples. If we managed to optimize the preprocessing performance I believed the GPU training times would improve significantly. In the following picture you can see the details of profiling results. Keras training goes to sleep, when it has no data ready to train on.
After identifying a possible bottleneck I decided to modify the preprocessing a bit to see how much can be improved. I saved the preprocessed data from the generator into memory and created a new generator taking prepared samples directly from the memory. In the chart below you can see the comparison of times it took to perform a single run over the complete dataset. The speeds improved a bit. The bottleneck was removed and the model was now taking samples from the queue smoothly and without waiting. But why is the GPU on Amazon still slower than CPU on my laptop? That is quite mystery.
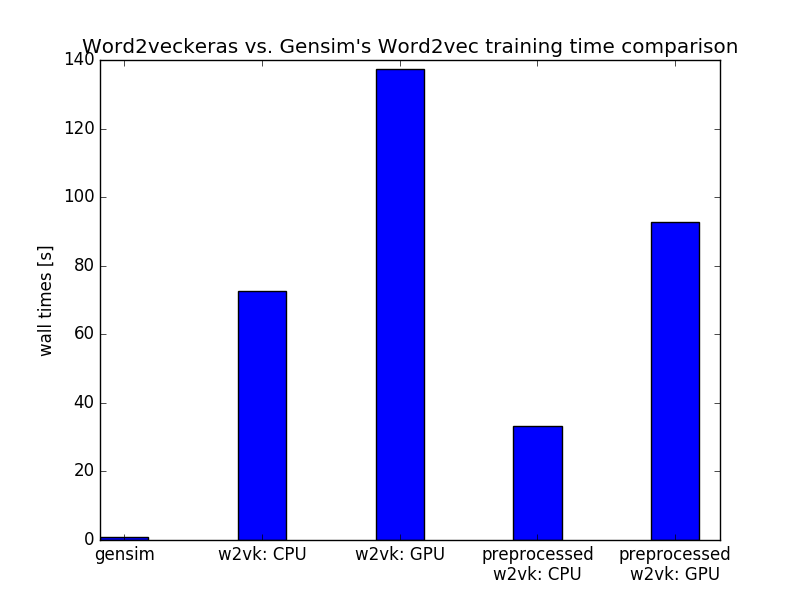
Table with Word2Vec benchmarks:
| generator threads | processor threads | processor | code | words/sec | |
| Gensim’s Word2Vec | 1 | 4 | Intel Core i5-6200U | CBOW | 930k |
| Word2Veckeras on Theano | 1 | 4 | Intel Core i5-6200U | CBOW | 16k |
| Word2Veckeras on Theano
(partially preprocessed) |
1 | 4 | Intel Core i5-6200U | CBOW | 36k |
| Word2Veckeras on Theano | 1 | 1 | Nvidia GRID K520 | CBOW | 8k |
| Word2Veckeras on Theano
(partially preprocessed) |
1 | 1 | Nvidia GRID K520 | CBOW | 13k |
| Word2Veckeras on Theano | 1 | 2 | Nvidia GRID K520 | CBOW | TBA |
| Word2Veckeras on Tensorflow | 1 | 2 | Nvidia GRID K520 | CBOW | TBA |
In August Intel Labs released an interesting paper where they propose an improved parallelization technique for CPUs showing, that the the CPU is comparable to GPU in terms of speed. They provide many benchmarks comparing the current the state-of-the art GPU Word2Vec implementation BIDMach, which achieved 8.5M words/s on Nvidia Titan X. The GPU efficiency of computation was only half of that of the CPU, but the performance was superior. Other benchmarks in the paper include distributed w2v on multi-node systems. In the following table you can see the state of the art speed performance on a single machine from Intel’s paper.
Table with Word2Vec state-of-the-art implementations’ performance:
| generator threads | processor threads | processor | code | words/sec | |
| BIDMach, Berkeley paper | 1? | 1 | Nvidia GeForce Titan-X | BIDMach | 8.5M |
| Intel paper, code Aug 2016 | 1? | 272 | Intel KNL (Xeon Phi) | Intel | 8.9M |
Summary of Word2Vec parameter set-ups used in experiments:
| dimension | negative samples | window | sample | vocabulary | |
| Gensim & Word2veckers benchmark | 100 | 5 | 5 | 1e-3 | 15,173 |
| Intel + BIDMach | 300 | 5 | 5 | 1e-4 | 1,115,011 |
I think it could be potentially very interesting to test other tools like Keras and see if we get better results running the GPU as one would expect. For example, a Tensorflow Word2Vec implementation might be worthwhile comparing next. A related article about FastText, an extension of Word2Vec, was published recently on our blog by Jayant Jain. Another interesting read is an older article by Radim about the optimization of Gensim’s Word2Vec.
To conclude this article I would like to thank Lev and Radim for their support and regular meet-ups, I have very much enjoyed my exploration of Word2Vec.
