RARE Technologies
RARE Technologies
Gensim Survey 2018
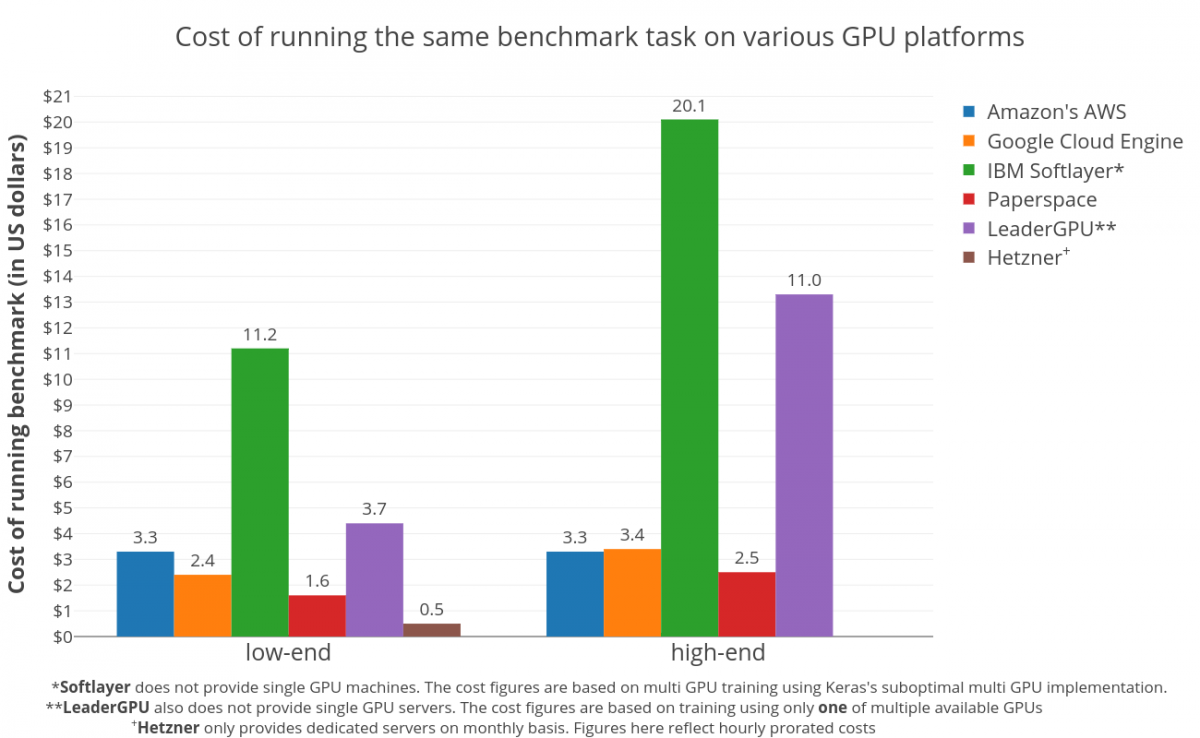
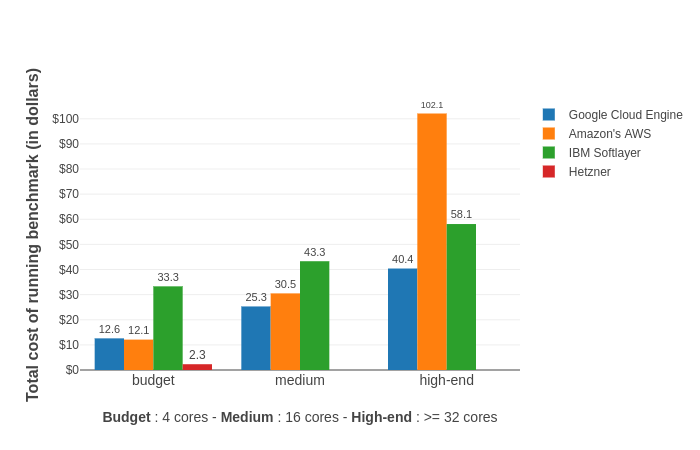
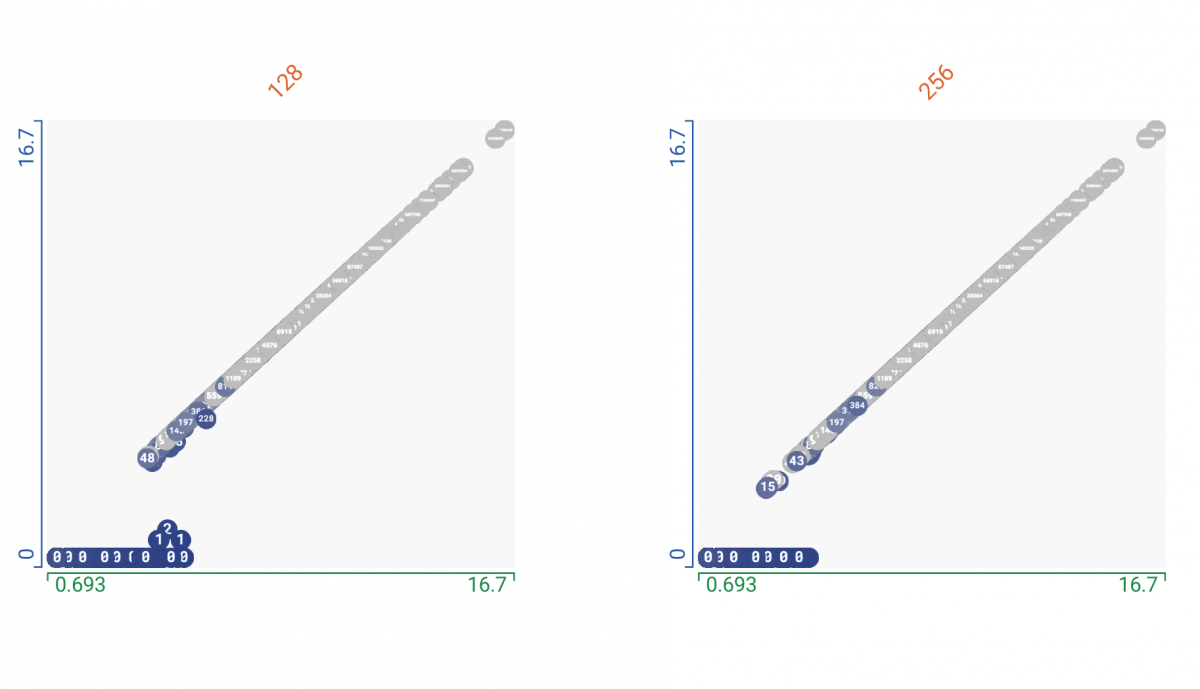
Last month, we ran a survey among Gensim users to get a better idea what delights and annoys you. The ~7 minute survey was completed by 448 people. That’s a great juicy sample, big thanks to all who participated! Full detailed statistics here; in this post I’ll summarize what we found and what it means for Gensim.